
Predictive Maintenance applies condition monitoring techniques to discover potential failures. While finding a problem before it becomes a failure is good, companies can end up with so much work that maintenance backlog skyrockets, maintenance costs blow-out and people burn-out. Understanding when a predictive maintenance strategy can cause uneconomic maintenance, or why condition monitoring can produce unending failures, is vital if you want reliable equipment with low maintenance cost.
Keywords: predictive maintenance (PdM), condition monitoring (CM), reliability centred maintenance (RCM), opportunity maintenance, preventive maintenance (PM), breakdown maintenance (BM), precision maintenance (PrM)
It’s interesting to watch what happens to a company that takes on a predictive maintenance strategy using condition monitoring techniques. Companies do predictive maintenance because it promises reduced operating costs. The savings supposedly arise by doing corrective work as less expensive planned repairs, and not costly breakdowns.That is often not what happens.
When you replace Preventive Maintenance with Predictive Maintenance you go from a state of certainty to a state of uncertainty. Once you start monitoring for failure initiation in parts you will at times take equipment off-line to address serious potential failures. Since these failures will be randomly timed you end up taking equipment out of service randomly in response to the size of risk associated with that failure. These event increase in number with aging plant and will cause Maintenance to become reactive. They also produce urgent, rushed procurement demands on Stores. In the coming years units will be coming down haphazardly without consideration for the most cost effective maintenance. Predictive maintenance leads companies into component/assembly focused maintenanceinstead of doing the most economic maintenance.
The beauty of PM is that parts at risk are all renewed together. Without doubt there will be parts replaced that will have lasted longer and money is spent unnecessarily. But that should not be the driving importance; it depends on what strategy delivers maximum availability AND least operating life cycle cost. Here we must consider the economics; what is the most profitable mix of maintenance strategies regardless of when parts are replaced. This depends on the cost of a particular failure and whether it matters if equipment comes down at any time or it must have a sure length of operating time. First you need to know the cost impact of each failure before you can decide whether it is best to use PM or PdM to minimise operating costs.
An additional and vital consideration that impacts maintenance strategy selection is what your maintenance providers can cope with. PM provides certainty, regularity and standardisation for Maintenance, whereas PdM means uncertainty and this will distress your maintenance providers. Uncertainty leads to higher spares holding in order tobring comfort to people. PdM will, in time, cause higher use of subcontracted services because your own people are busy with more important predicted failures, or they do not have the expertise to do the condition monitoring or to correctly interpret the meaning of the CM results.
No matter how your maintenance arises, time based, usage base, breakdown based or breakdown prediction based, you will have people involved in the repair. Involving people guarantees human errors and ignorance will act to produce defects that will ruin your machines. What is your strategy to protect against that?
Increased Number of Machines at Risk
Figure 1 shows the survey results of paper mill equipment vibration levels taken nearly two years apart. After two years they had more problem machines than ever before. The number of machines with high vibration increased from 20% to 30% (8mm/s is a rough running machine). What happened to cause that—isn’t predictive maintenance meant to reduce problems? (Today we still suffer as they did in 1989/90. What is it that sustains our errors across decades?)
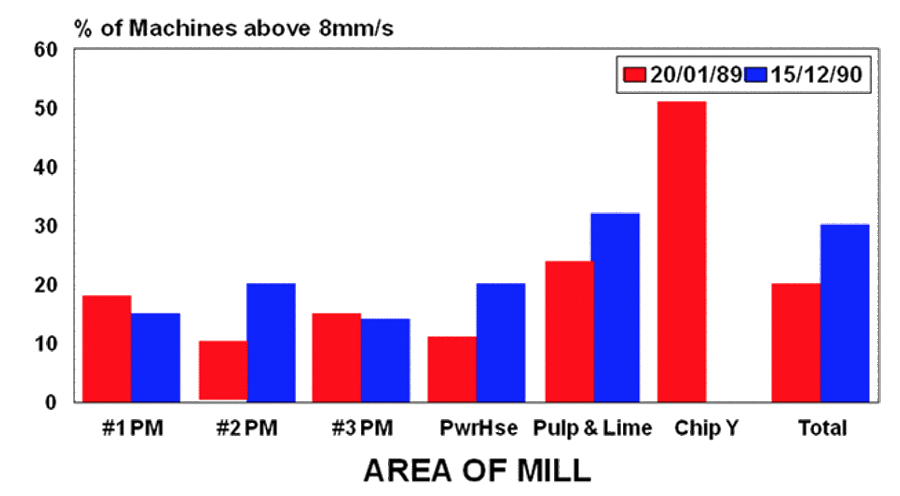
Condition monitoring does not fix machines. Condition monitoring does not stop failures. Condition monitoring only lets you find problems before they become a failure. The paper mill used CM to find pending failures but theyrepaired their machines poorly and so they always had pending failures. Their maintenance problems grew 50% in two years as people rushed from corrective repair to corrective repair; fixing one problem while starting the next one.
Figure 2 is a marketing photograph highlighting the use of thermal imaging to spot potential failures. You can see how the image shows-up the hot centre cable that we would not otherwise see. It’s an impressive condition monitoring technology giving us new knowledge of the behaviours of our plant and equipment (and of the people that operate and maintain them).

From the thermographic survey a maintenance work order would have been raised. If the issue was urgent (which is likely since CM makes it very clear how risky a problem really is) the job would go to the top of the work order pileand be scheduled for rectification as soon as necessary. Condition monitoring found the problem and we use maintenance to fix it before failure. That is how predictive maintenance is meant to work.
The dilemma is that Maintenance is already busy. To do this high priority corrective work job Maintenance is forced to remove a lower priority job. Previously scheduled work is postponed and all its planning and preparation wasted.The high priority forces Stores to order parts at once; even paying a penalty for quick delivery. Urgent CM-generated corrective work orders get done and less important work is postponed for some other day. Unwittingly CM sets a trap for us— we do urgent work to correct failures by delaying failure-preventing work.
The other option to do high priority work when you do not have resources is to subcontract it out. When corrective work goes to subcontract you pay more than if it were done in-house. The job also becomes logistically more complicated because of all the extra preparation and authorisation needed to get external people into a site to do work.Unknowingly CM sets two more traps for us—maintenance focuses on doing urgent work, and subcontracted maintenance costs rise.
Wrong Life Predictions for Wearing Parts
A common mistake with predictive maintenance strategy is using CM to predict replacement of wearing parts. A case study of conveyor belts in an ore processing plant explains the situation.
Three critical conveyor belts failed between scheduled 6-weekly shutdowns. The Maintenance and Condition Monitoring Groups knew of the poor condition of the belts and were waiting for the next shutdown to change them.Eighteen months earlier the operation had changed to a predictive maintenance strategy for determining when to change belts. The operation went away from time-based replacement and did belt thickness testing to conditionmonitor belt life. The Condition Monitoring Group collected test results at each 6-weekly shutdown and trended them on graphs. With sufficient data points they projected the time to the end-of-belt life and scheduled replacement in the shutdown due before that date.
Investigation of maintenance history showed some belts degraded to minimum thickness within 3 to 4 weeks, especially with aggressive ore or if failure-causing events like seized rollers occur. The degradation curve for conveyor belts could fall so rapidly that failure could happen in the period between shutdowns. The effect is shown in Figure 3 where the middle curve shows rapid wear between shutdowns and the bottom curve is wear over a longer period with failure again happening between scheduled shutdowns.
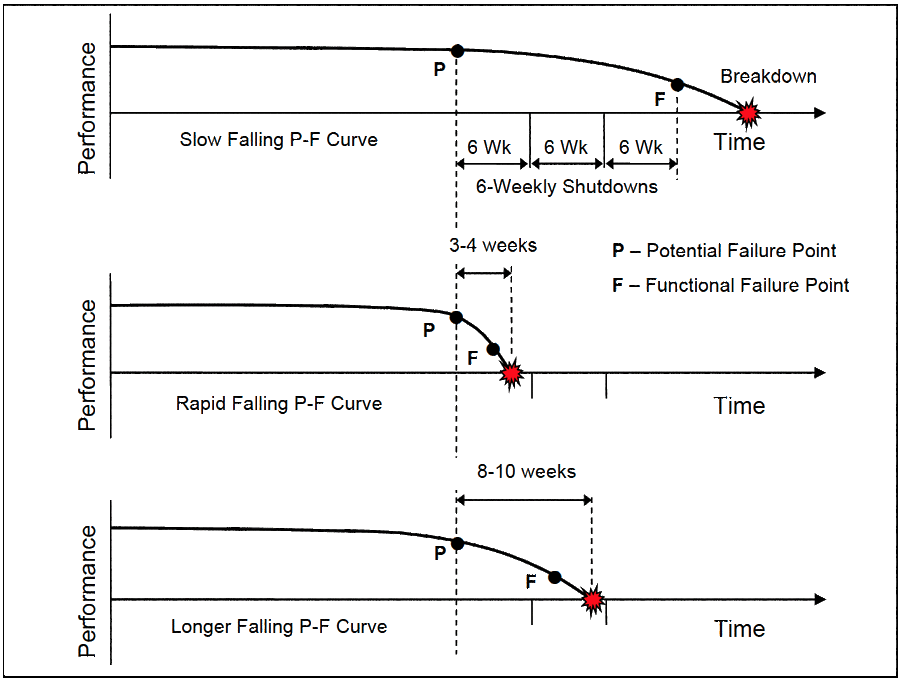
When wear rates are wildly variable the use of CM for prediction provides a false sense of security. Though prediction is the purpose of predictive maintenance, predicting from condition monitoring results is only viable if degradation is reliably consistent, the test parameter trended actually reflects the real rate of degradation and the inspection period is at least three times shorter than the shortest P-F window. Where there is wide variability in thedegradation rate and inspection periods are long, then unobserved and unexpected failures will occur between the scheduled condition monitoring test dates.
This was the case with conveyor belt thickness monitoring. The assumption had been made that the rate of belt wearwas sufficiently constant to be trended so the functional failure date (Point F) could be forecast. But this was never the case, since the rate of belt wear depended on changes in ore material properties, how well the belt tracked, inherently designed belt strength, the cleanliness of the belt, the presence of ‘banana peeling’ rollers that removed three months life in a few days, the effectiveness of scrapers, ore loading rates and impact forces on landing, the size distribution of ore lumps, along with other factors. Due to the variability in the wide range of belt wear causes, compounded with random human errors in procurement (wrong belts purchased) and maintenance tasks (wrong settings for scrapers), the date to replace a belt using belt thickness projections was often wrong by large margins.
The control of degradation rates becomes critical if the degradation curve is to be surely extended across long CM inspection windows or across long periods without outages. Degradation control for conveyors includes correct, steady belt tension, maintaining belt cleanliness, rapid fixing of scrapper problems, replacement of seized rollers, steady throughput rates, and other factors that stress and damage conveyor belts. Where the inherent design of a belt does not guarantee long P-F curves, it is necessary to replace the belt with one constructed of materials and thickness that surely bridges the necessary time window.
A question that arises at point P is when to replace the belt? In the top curve of Figure 3 the degradation is steady and controlled and the choice is easy. Where wear rates fluctuate you are troubled in your decision because nothing is certain. You are now in a risk scenario and the situation takes a risk management perspective. The decision will be the one that costs the least amount of money should the belt fail at any time. A spread sheet model is used to calculate the total business-wide costs of changing the belt on failure and another model to calculate the total business-wide costs of replacing the belt in a planned shutdown before failure. Because you don’t know how lucky you will be in future (since wear rates are out-of-control and change quickly at any time for many reasons) you do the least expensive one. Over a long period of time (maybe as much as a decade or more) this strategy costs you the least amount of money.If the cost of a breakdown is so astronomic it dwarfs shutdown cost you are in the fortunate position of justifiably changing the belt before failure is hardly possible. In this case, the promising pay-off from taking the risk to run the belt for a little longer can never pay for the money lost if a breakdown happens. This is a great place to be for a maintenance manager— never have breakdowns—because you make more money by always renewing equipment well before it gets old and tired, rather than hoping to get a little more operation out of equipment with a rising and fluctuating risk (luck eventually turns against you—perhaps many times). Table 1 indicates the options available to you depending on the P-F period.
| Scenario | Spares Holding | Maintenance Strategy | Degradation Management |
| Long P-F Curve | Order spares at Point P (later if Supplier can deliver in time) | Condition monitoring checks spaced wide apart. Rectify on aplanned shutdown. | Steady, stable, consistent plant operation |
| Short P-F Curve | Keep full set of critical spares on-site (make them emergency spares only for this job) | Many condition monitoring checks, or run-to-failure. Wellplanned replacement, fast repair intervention at any time. | Prepare for fast plant handover to Maintenance |
Investigate the maintenance history of your equipment and identify its failure modes and the modal degradation curve behaviours. If there is insufficient equipment failure history then instigate data gathering of other similarequipment’s history used in your industry. Their degradation will be different to what happens in your operation so also start collecting physical measurements of thebehaviour of your equipment’s’ wearing parts to build evidence of trends in your operation. Once you have a good understanding about how your plant fails you can select suitable CM technology and appropriate inspection periods to identify future problems.
Building sound and complete financial risk models that let you deeply understand the business impacts will take the guesswork out of maintenance decisions and clarify what you ought to do. Effective maintenance is not just about creating high reliability; it is also about knowing the cost consequences of your maintenance strategy.
Predictive Maintenance Strategy without Economic Maintenance Considerations
Unfortunately there is still another trap with predictive maintenance—using alarm limits to trigger corrective action.Eighteen months into its predictive maintenance strategy the ore handling plant had so many impending failures it caused uneconomic maintenance activity.
The entire plant was monitored using a proprietary machinery monitoring system. Regular condition readings ofseveral thousand points were taken and entered into hand-held recorders by the CM Group then downloaded into the monitoring system and tracked. When conditions at a point were bad a work order was raised to rejuvenate it.Innocently the machinery monitoring system turned maintenance focus toward maximising individual part life without considering the economic impact of maintaining parts in isolation to the rest of the equipment.An example was the coil springs on a series of vibrating screens. Each spring-set height was monitored and when the screen got too low the weak spring-set was replaced on a work order. For a screen with six sets of springs that degraded at different rates this was a sure way to get six work orders raised and have six outages. It was an uneconomic way to care for such equipment even though people were following seemingly good predictive maintenance strategy. The better approach would have been to replace all springs when the first one had degraded to warning level (not alarm level—that is far too late. If you wait for alarm levels before you act everything you do will be an urgent priority—a great recipe to create reactive maintenance). In the outage to replace the first set of springs new springs should be installed throughout. The equipment will then run for a long time without spring slackening being a concern. This is good economic maintenance practice.
A part-by-part monitoring approach easily produces an uneconomic part-by-part replacement practice in an operation.This is addressed by developing tables for each equipment type (mechanical, electrical and control equipment) listing all parts to be replaced whenever one in the list needs to be replaced (e.g. when one spring-set on a vibrating screen needs replacing then fit all new spring-sets throughout. When one screen needs replacing then fit all new screens throughout.). In this way the whole equipment’s reliability rises because the old tired parts are all replaced with new parts that have a full fresh life ahead of them. There will be a one-off higher initial maintenance cost and longer downtime (actually it’s an investment in reliability, not a cost) but it is more than paid-back by the greater throughput from the longer production runs without stoppage (Beware to replace wearing items as a complete set and do not leave an old wearing part against a new part, as the new part will wear rapidly and the old part will fail sooner from distortion stresses as it tries to marry into the new part.)
Figure 4 is a simple example related to a centrifugal pump. The table identifies what other parts to replace whenever a listed part is replaced. The failure curves show the economic logic of the decision. If the worn parts are not replaced the pump will next breakdown when one of them fails. But if all parts are replaced new to precision maintenance standards there is a high chance of a long, trouble-free run.
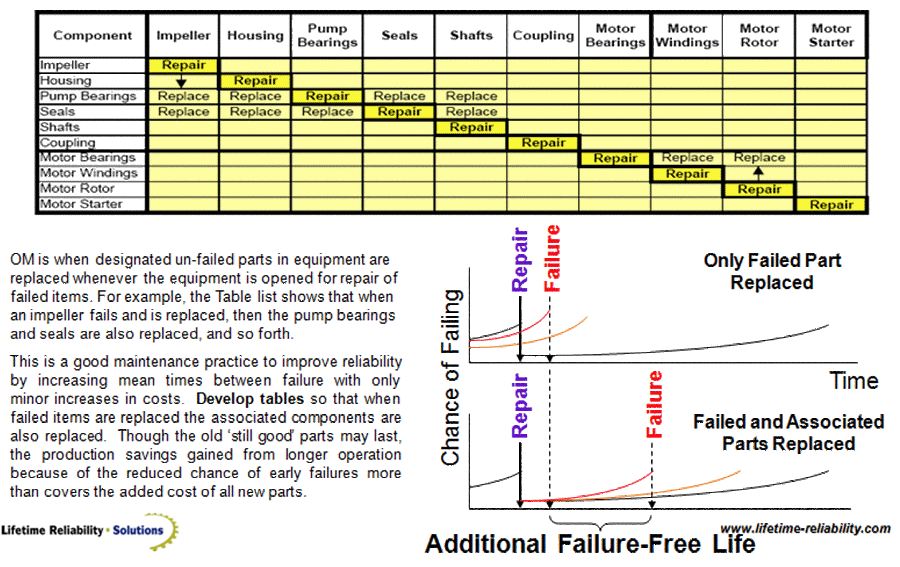
By raising work orders based on alarm limits of parts you introduce ad-hoc maintenance. Machines and equipment will always be taken out-of-service to be worked-on urgently. You might arrest a breakdown, but everyone is maddeningly rushed. Wild swings in procurement will then produce poor Stores Management performance.Multiple maintenance jobs are done separately without looking for opportunities to optimise resources.
Do not let such ‘point-by-point repair’ situations arise. Where consequences from equipment failure are serious do a cost analysis of a failure. If breakdown is a disaster then proactively renew all items at risk as Preventive Maintenance—don’t gamble on Predictive Maintenance; if the loss from a failure is far more expensive than the small cost of early replacement the choice is clear. The closer you are to the functional failure point of any part in a machine the more urgent and sensible it is to get all the old items out and put new ones in. Even if you are wrong and not all parts are close to failure, the cost of replacement is negligible to the cost of letting a failure happen. Analyse the whole plant and make a list of equipment that is always to be changed-out with new (or with a fully refurbished unit) at any sign of failure. Don’t let old and tired equipment stay in use if it is cost effective to replace them before end-of-life approaches. (NOTE: Do not apply this principle without first checking the economic sense of renewal in the particular situation under consideration. Clearly it is not sensible to waste money. A spreadsheet costing analysis clarifies what you ought to do.)
The one proviso is that all Preventive Maintenance work must, as a minimum, meet the most stringent of the parts’ specifications and quality requirements used in the equipment (e.g. a tyre coupling is a part of a centrifugal pump set and can handle 1mm misalignment and still work, but the pump and motor bearings might only handle 0.01mm misalignment, which makes the tyre coupling manufacturer’s alignment nonsensical in the situation; it is the pump and motor manufactures’ requirements that must be met, not those of the coupling). During repair dormant equipment failures are introduced through misunderstandings and human error. This is protected against by using awritten work quality standard to which every maintenance task is done; so that people know what is right and a task can be checked and proven to be accurate. The lowest standards and specifications to use are those of the originalequipment manufacturer. If you keep your equipment to the requirements of the manufacturer you can achieve its inbuilt reliability.
Drowning in Condition Monitoring Inspection Requirements
At the ore handling plant thousands of points had been included in the weekly inspection routes for the Condition Monitoring Group to do. The inspection routes had so many points to measure and record that it took too much time to do them (nearly 800 points in one route, which at one minute per point would take an unrealistic 13 hours non-stop work). Work orders for CM inspections were returned to the Planner undone. Regularly weeks had gone by whereinspection work orders for the same route or equipment were missed. Instead the inspection routes turned into walk-throughs where only exceptions of note are recorded in the trending system. To reduce the high number of alarming points (it was common to return from an inspection route with 40 or 50 points in alarm), the warning and alarm settings were set higher so only serious problems on equipment were identified for action. These points received top work order Priority 1 because the job was now vitally urgent. (What more certain way is there to ensure that you always have Priority 1 problems.) Work planning and work quality was then rushed and jobs were shoddily done, guaranteeing another future repair.
Underlying misunderstandings of degradation led to thousands of points being checked each week. No analysis had been done of the shortest and average P-F window for each point. (If a P-F window is two years long you only need inspect the degradation every six months. If the P- F window is a month, then inspect every week. It is better to group all CM inspection rounds by P-F window size and inspect equipment only when truly necessary.) Quite unintentionally predictive maintenance produced sure ways to always have serious problems and a lot of maintenance. Once the practice became to only detect and respond to urgent problems then maintenance naturally became reactive, ineffective and inefficient.
A Serious Shortcoming with Reliability Centred Maintenance
Be wary of Reliability Centred Maintenance (RCM) because its prime philosophy is to replace time-based and usage-based maintenance with condition-based maintenance. The sad stories from above should now set-off flashing alarms in your mind of what CM can lead you into. RCM can only release its benefits if the degradation rate of failure modes is suitably consistent.
Consultants advise the positive benefits of RCM: it reduces PM workload, removes critical spares, and uses lower cost PdM activities. Everyone will laud the apparent progressive thinking and the sudden reduction in maintenance costs it generates. But on equipment with variable rate failure modes corrective maintenance work gradually rises.Sudden high priority work makes you postpone failure-preventing work and eventually you find you areregularly taking equipment out-of-service doing ‘patchwork maintenance’. Be very wary of what RCM can do to your work processes over the succeeding years of its introduction—keep using PM strategy where economic; don’t replace it with uncertain PdM practices unless there is sure money in it.
Use Condition Monitoring for its Greatest Benefit—Defect Elimination
The greatest benefit condition monitoring provides is the ability to see what we cannot see. Predictive Maintenance uses that capacity to identify impending failure. But where there are too many impending failures you drown in urgent work. Fortunately there is a truly powerful reliability improvement benefit that CM provides if we are wise to always use it.
Figure 2 is reproduced in Figure 5. The thermal image shows us a problem with the cable. There should never have been a problem to start with. The cabling should have been perfect at the beginning; it should have been done right-first-time. Had it been done right at the start we would get fifty years trouble-free operation. Used ‘at the start’ is where CM is most powerful. The thermal imaging camera should have been used by the capital project group on the day the equipment was first commissioned at full load. The problem would have been fixed forever the next day.After each and every maintenance intervention your equipment must be condition monitored to prove the intervention was done right-first-time.
Condition monitoring used to check operating plant cannot deliver reliability because you only find problems; those impending breakdowns that must now be urgently fixed. If you want to stop your maintenance troubles use apt condition monitoring at start-up to find those defects that people mistakenly built-in; then fix the flaws so they do not become your future failures.
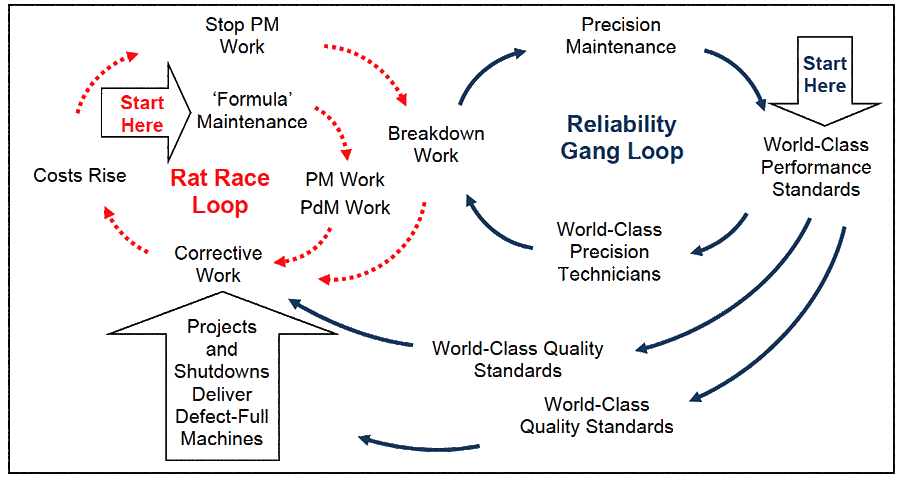
How to Escape the Maintenance Rat Race
The ore handling plant case study was a consulting assignment to identify how to get the operation out of trouble. As well as advising the need to know their parts’ degradation rates and to master degradation management, I suggested they start a two-man Reliability Gang supported technically by the Condition Monitoring Group. The two-man gang would not generate work for someone else to do. They would be world-class, precision skilled technicians who fixed machinery properly. They would plan with the CM Group how to correct problem equipment and use precision methods to bring reliability into the operation.
Figure 6 represents the approach of spinning-off a dedicated Reliability Gang separate to the maintenance group fighting in the ‘rate race’. Bit-by-bit the Reliability Gang consumes the maintenance problems until there are no more. Machine by machine they make them work perfectly. Defect elimination is the strategy they use, precision maintenance is the standard they work to, and condition monitoring is used to prove that reliability is built into every plant and equipment item. The Reliability Gang feed their learning into the maintenance group (and throughout the business) via the Condition Monitoring Group, so that eventually everyone learns how to deliver world-class reliability performance.
Conclusion and Recommendations
Doing Maintenance well includes making good economic decisions. Choosing BM, PM or PdM is best done by applying sensitivity analysis (‘what-if’) in a financial risk analysis model of equipment operating life and not by only using a decision flowchart unconcerned with economics.
To make predictive maintenance successful you need to deeply understand the degradation modes of your equipment and any variability in the associated P-F windows. When multiple failure mode degradation curves fluctuate madly component P-F windows never align. Your machines will always come-down for maintenance before some part breaks. Your procurement will be out-of-control. You have high maintenance costs with low availability.
Replacing time-based and usage-based maintenance must first be justified by the economics of the maintenancestrategy; something that RCM does not demand. Predictive Maintenance allows failures; in fact it designs failures into your operational processes because it is a strategy that cannot by itself prevent failures. Whereas Preventive Maintenance, with its time-based and usage-based requirements, ensures replacement or renewal is done before failures can happen. You can justify using Predictive Maintenance if the cost of a breakdown missed is not more than replacing or renewing the item well before failure. If a breakdown is horrendously expensive compared to the cost of regular replacement, then use PM and always replace when due. The right maintenance strategy is the one that delivers most operating profit over the life cycle.
Beware of the limitations of Predictive Maintenance strategy—it is fickle for equipment with fluctuating rate wearing parts (stabilise the wear rate first); it will throw your work management and stores management processes into chaos from ad-hoc work order generation, and trick you into replacing economically sound PM strategy with failure-permitting CM practices.
Preventive Maintenance strategy is inherently better at reducing breakdowns than Predictive Maintenance because it demands renewal before failure. Unfortunately Preventive Maintenance strategy fails because of ignorance and human errors that destroy machines. World-class machinery reliability lives in the precision regions below 10 micron, but most professional engineers don’t know how important 10 micron is, most machine shops are not reliably accurate below 25 micron, most repairmen cannot repeatedly deliver 100 micron accuracy, and most operators cannot constantly meet 1,000 micron exactness. As a consequence of inaccuracy reliability is lost.
If equipment has stable degradation curves a time-based and usage-based PM strategy with Precision Maintenance is much easier to run and manage than a Predictive Maintenance strategy where random events drive maintenance response. Though PM is potentially simpler, easier and naturally prevents breakdowns, it needs Precision Maintenance to be truly effective because we must control human error. PdM identifies potential failures early but needs Precision Maintenance to prevent failures endlessly repeating as people introduce defects when they repair the equipment. It is no surprise to learn that for lasting success with either Preventive Maintenance or Predictive Maintenance your organisation must also do Precision Maintenance.
You would get a clearer understanding of your maintenance strategy options for creating the least operating life cycle costs if you first financially modelled the range of maintenance strategies available on each equipment and its assemblies (within the known operating constraints) . Develop a table like the one below and determine the company-wide Defect and Failure True Costs if each strategy were applied on every assembly in an item of equipment. Once you know the least cost maintenance types to use you can knowledgably and confidently select your maintenance activities to produce maximum operating profits. You can learn more about identifying all your total defects and failure costs from the article at the Plant Wellness Way website titled, Instantaneous Cost of Failure.
| EquipmentID | AssemblyID | Cost of Assembly Failure | DAFT Cost of BD Strategy | DAFT Cost of PM Strategy | DAFT Cost of PdM Strategy |
My best regards to you,
Mike Sondalini

Leave a Reply