
This article is Part Two in my three part series about “PM” programs.
Reliability Centered Maintenance (RCM) is the world’s leading method for identifying maintenance and other activities required to sustain reliable performance of physical assets. If you want a proactive maintenance program that really works, then Reliability Centered Maintenance is the most thorough approach you can take to get there.
Since the 1970’s it has been responsible for huge improvements in airline flight safety – crash rates today are 1 / 120th of what they were before RCM was introduced. Elsewhere, particularly in critical applications like nuclear power, it has produced similarly impressive improvements in reliability. That leads to more uptime, in turn resulting in greater production and revenues, lower costs, improved safety and environmental compliance.
RCM was initially created by Stan Nowlan and Howard heap when they published their studies in a paper entitled, “Reliability Centered Maintenance” in 1978. Since then a number of variations have arisen, John Moubray’s RCM2 perhaps the most successful and widely known. His method, was developed for use in industrial applications, is compliant with SAE JA-1011, the standard for RCM in the industrial applications.
RCM is a team-based method that combines the knowledge and expertise of maintainers, engineers and operators. The team (usually 3 to 5 people) analyses one system (not necessarily a piece of equipment) at a time. Depending on complexity of the system (not size) it can take anywhere from 10 to 15 meetings (each 3 hours long). In those meetings a trained facilitator asks questions about the system and gets answers from his team of experts. During that process they make decisions on future actions that are both technically sound and “worth it” from the perspectives of cost and risk.
The seven questions are:
- What are the functions of the asset and their desired levels of performance?
- What are the failed states associated with each function (i.e.: functional failures)?
- What are the failure modes that lead to those failed states?
- What are the effects of those failure modes? (i.e.: what happens if we do nothing to prevent them from occurring?)
- How do those failure modes matter? (i.e.: safety, hidden, operational, non-operational?)
- Can we do anything proactive to predict or prevent the failure?
- If not, then what can we do? (i.e.: run-to-failure, failure finding, re-design or some other one-time change?)
Those questions appear easy enough to answer but there is a great deal behind each of them. For instance, the very first question asks about functions. The functions are the things the system does for us. They are NOT merely a description of what the system “is”. There is usually a primary function (i.e.: the main reason we have the system) as well as a number (sometimes many) secondary functions (e.g.: environmental, safety, control, containment, appearance, protective, economy, efficiency and sometimes even superfluous functions we really don’t want). All functions must be listed and then standards of performance associated with them. The standards define what we “want” from the system, not what it is capable of doing, so engineering specs are often not particularly helpful at this stage except perhaps as a sanity check to ensure we are not asking more of the system than it was designed for.
Many technical people are so used to dealing with “what” a system is that they forget what it does. Here we are interested in what it does and much less in what it is. For instance, a single function like, “to contain the pumped liquid” implies an absolute standard (i.e.: it cannot leak at all) and it applies to all components that have a containment function (e.g.: housings, pipes, gaskets, valves, seals, etc.). It is not necessary to list all the components at all. Operations people grasp this right away because it fits so well with their perceptions, but technical people often struggle with this different perspective.
Likewise, each of the RCM questions is “loaded” – you really need to understand what is being asked, in order to get the right answers.
The first four questions are the equivalent of performing a Failure Modes and Effects Analysis but again, it focuses on functions, not components. The last three questions take the user through a decision logic (a diagram is used for this) to help arrive at logical and worth-while decisions about what actions can be taken. The diagram is very efficiently structured so that the most likely answers are reached early. It also ensures that not only does the team arrive at technically sound decisions (i.e.: prevent only what is preventable, etc.) but also decisions that are worth implementing. It requires a brief analysis of risk or costs, depending on the nature of the consequences from each failure mode. If risk is reduced, or costs are lowered, then the decision is “worth it” to implement. If not, then the team continues to look at technical options until they are exhausted and it must accept run-to-failure or some sort of redesign (or other one-time change) as a default solution.
Once the analysis is completed its decisions must be put into practice. The various tasks, task frequencies and assignments of who does the work must be entered into the maintenance management work order system for automated triggering and issue of work orders. For decisions about technical redesigns the recommendations must be sent to engineering for further development work. If the decisions require training, rewrites of procedures or some other one-time change, those too must be carried out by the appropriate responsible authority.
Doing an RCM analysis requires collaboration among maintenance, operations and engineering departments. Getting the outcomes implemented requires those three as a minimum and often involves training, human resources, finance and possibly other departments. It is a “whole organization” process, not, as the name suggests, a “maintenance only” initiative. In fact, if it is approached with only maintenance it will not work.
So how do you get started with RCM? The diagram below shows a brief outline of a process for introducing RCM to a site:
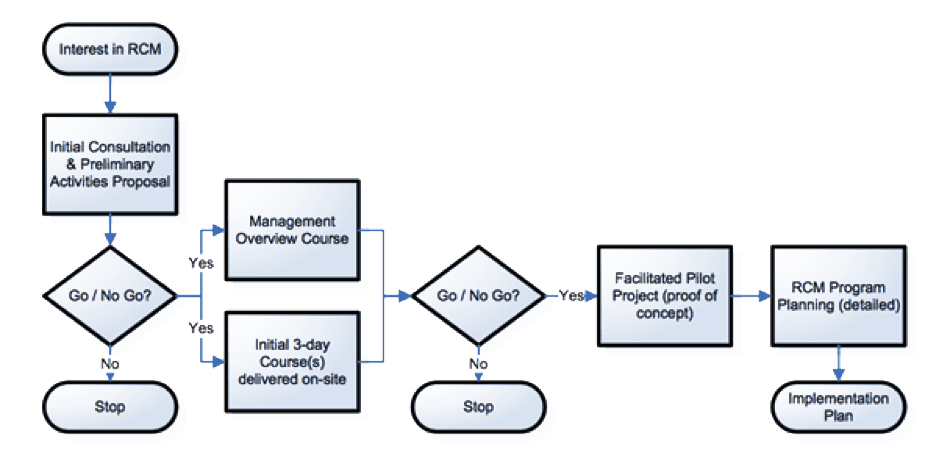
Assuming a decision is made to continue after the concept is proven, here is what a typical implementation plan looks like:
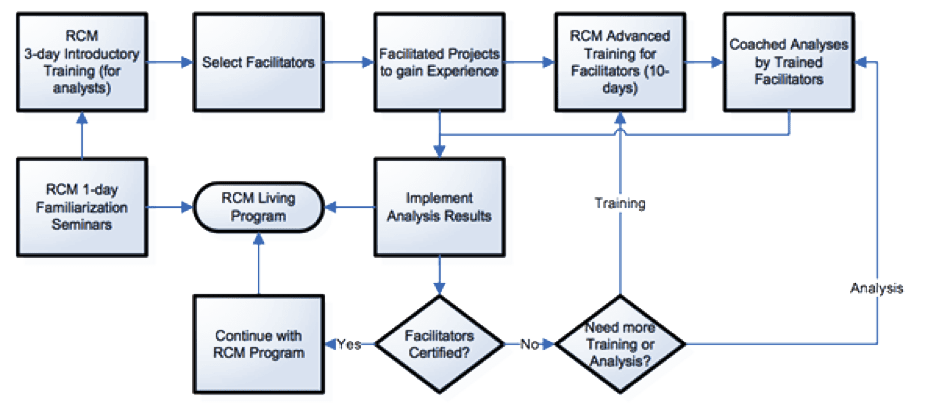
Anyone participating in the analyses needs to have the basic analyst training (normally a 3-day course). It is wise to carry out a few pilot projects early in the implementation and have an experienced facilitator from outside lead them. That will serve to prove the concept at the site and the experienced facilitator can set the standard that should be expected of the program. Effectively the facilitator demonstrates what “good RCM” looks like.
Anyone you choose to facilitate from your own staff needs additional training. There is a 10-day course on facilitation skills that is used to develop that capability. Following that the newly trained facilitator will need mentoring. The new skills will be unfamiliar and largely untested – he or she will need help to get fully comfortable and competent. Usually that takes 2 or 3 complete analyses while being mentored by an experienced RCM “practitioner”.
A “practitioner” is a highly trained and experienced RCM “expert” who teaches the courses and mentors newly trained facilitators. Usually the practitioner is from an outside agency specialized in delivering these services.
Getting started requires quite a bit of outside help if you are to do RCM correctly, efficiently and effectively. Reading the books on it and thinking you can run with the ball after that is a mistake that many have made. Those who have gone that route usually end up realizing that they are not getting the results they want, it is taking them far too long and consuming too many resources. Many of those simply give up and complain that RCM doesn’t work. That’s too bad for them. They’ve just thrown away an opportunity to get the sort of benefits that the airlines, nuclear power producers, military and other users have seen. Those failed users have failed themselves – often in the interest of keeping their up-front costs down. They’ve been penny-wise and pound foolish as the old saying goes.
Don’t cheap out. Once you have had the training, carried out pilot projects and begun to analyze your own systems you are ready to go solo without the outside help. From that point onwards the only help you are likely to need is to employ outsiders to deliver the training for new analysts. Again, it’s a false economy to think that you can use untrained analysts in your review teams, even with your own experienced facilitators and other experienced analysts on the team. Those new and untrained people will slow progress down considerably as you are forced to answer their questions about the method and explain the meaning of each question you ask. Learning RCM is like learning a new language – the language of reliability. It takes a bit of time and effort, but the rewards are huge.
To learn more visit Conscious Asset where you will find training, workshops, books, and resources.
Related
Preventive Maintenance “PM” Programs – Part 1 – The Basics (article)

Leave a Reply