
How to use Condition Based Maintenance Strategy for Equipment Failure Prevention
Most equipment failures have no relationship to length of time in-service. Most failures are unpredictable. But if you detect a future failure early, you can plan and do the repair cost effectively before it becomes a breakdown.
With only about 15% to 20% of your equipment failures being age related, and the other 80% to 85% being totally time-random events, how can you improve the uptime of your plant and facility? This article explains how to detect the random failures that make-up the vast majority of maintenance expense and production downtime by using simple, low cost condition monitoring methods.Keywords: equipment condition monitoring, random equipment failure, equipment failure patterns
Equipment Failure Probability Curves Showing The Six Time Related Patterns of Failure
With the introduction in the 1960’s of the first Boeing jumbo jets questions were raised about the sense of continuing with maintenance requirements based on the traditional ‘bath-tub’ curve maintenance paradigm present at the time.
Investigations were conducted of past aircraft maintenance history. It was found that all failures fitted one of six conditional probability (or likelihood of occurrence) failure curves. The USA Navy conducted similar investigations and confirmed the findings of the airline industry. The six failure patterns identified are shown in the Figure 1 below. The traditional bathtub paradigm (Pattern A) explained only 3% – 4% of failures.
(NOTE: There is a large question as to the accuracy of the Nolan and Heap 1978 Reliability Centered Maintenance report that first published the failure curves. The analysis mixed up overhauled equipment with new equipment, which are not comparable, and mixed up maintained assemblies with unmaintained parts, which also are not comparable. Certainly Pattern F is wrongly showing maximum failures at start-up. In reality most equipment will go when the start button is pressed or the key turned. At zero time Pattern F should begin much closer to the bottom left-hand corner of the plot and show a rapid rise in failures, signifying that most operating equipment starts but soon after start-up the failure rate rises from poor quality control during the life cycle to that point in time. It then follows that all the other failure patterns showing the curve starting high up the y-axis at time zero are also suspicious as to their accuracy.)
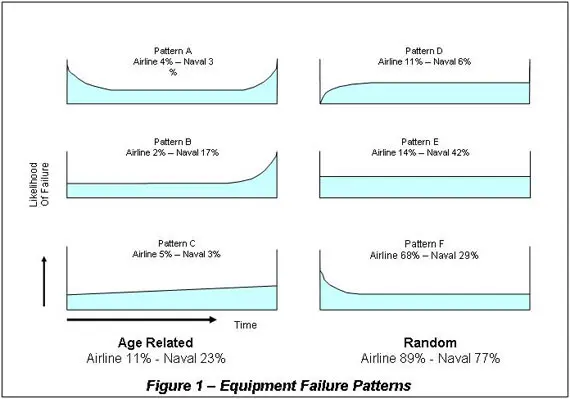
Whenever these results have been tested by other parties, their findings have confirmed the presence of the curves found in the original investigations. Though the proportions varied because equipment was in different situations and used in different ways. What seems clear is that with the equipment technologies available in the early 21st Century, equipment failures fit one of the six failure curves in Figure 1 but the proportions vary depending on engineering decisions and operational circumstances.
Here was definite proof that most failures were not age-related, where the equipment failed because of length of use. It meant that time-based preventative maintenance was pointless in most cases. ‘Age-related use’ includes stress fatigue failures (e.g. shafts breaking, springs breaking, boiler tubes leaking), erosion/corrosion failures (e.g. material erosion, metal corrosion), wear-out failures (e.g. car tyre tread wear, packed gland leaks) and other such failures where the length of operating time contributes to the eventual failure.
Non-time related failures were unpredictable! Time in service had no influence on 77% to 89% of the failures. This is not the same as saying that there as no reason for the failure. There will definitely be reasons for a failure, but you cannot predict when there will be a failure based only on the age of the equipment. For the vast majority of equipment you need to base maintenance on non-age related factors.
Most equipment assemblies and components eventually settle into a long period of chance failure. About 15% to 20% of maintenance will repeat based on age-related factors. You will see these in work requests for the same repair again and again over a period of years.
You find time-related failures by looking at your work orders on each item of equipment for as far back as you can and creating a Pareto Chart of its failure history. You can also get good answers by asking your long-serving maintainers and operators what keeps failing on each piece of equipment.
About 80% – 85% of your repair work orders will happen randomly. You cannot predict a date when they occur. But you can detect that they have started. It is possible to use the changed condition of the equipment to tell when a failure is due.
Equipment Condition Monitoring
Starting from new, a part properly built and installed into equipment without any errors, will operate at a particular level of performance, which ideally is at its design requirement. As its operating life progresses degradation occurs. Please do not assume degradation is normal and nothing can be done about it. This is not the case. In fact equipment failure should never happen! The acceptance of equipment failure as normal is an expensive misunderstanding to make.
Regardless of the reasons for degradation, the item can no longer meets its original service requirements and its level of performance falls. By detecting the loss-in-condition of the item you have advanced warning that degradation has started. If you can detect this change in performance level you have a means to forecast a coming failure.
Figure 2 below represents the ‘typical’ degradation process experienced by equipment. Following a period of normal operation, where the item has been running smoothly, a change occurs that affects its performance. The earliest time where you can detect the degradation is called the P-point, or potential failure point, since after this time the item can potentially fail at any time. This change gradually, or rapidly in some cases, worsens to the point that the equipment cannot reliably and safely deliver its service duty. At this stage the item has functionally failed, i.e. it is not delivering its required performance, and the location is called the functional failure point or F-point. If it continues in operation the part will fail and the equipment will stop working.
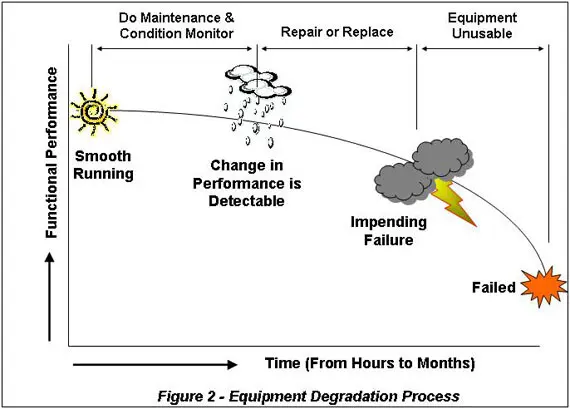
By using the ‘tell-tale’ evidence of changing equipment performance due to degradation, you can detect a failure and act to address it before an unplanned production disruption occurs. How soon you can detect the change in performance and spot the P-point depends on the condition monitoring technology that you use.
There are many ways to identify a change in equipment condition. Some commonly used ones are changes in vibration, changes in power usage, changes in operating performance, changes in temperatures, changes in noise levels, changes in chemical composition, increase in debris content and changes in volume of material. You can be as creative as you want in developing ways to warn you of future problems.
The most important issue is to spot the tell-tale signs early so that you have time to plan and prepare an organised and least cost correction. Once the equipment is broken you will have to spend whatever time, money and resources it takes to get it back in operation fast.
This explains why the leading companies have created a ‘condition monitoring technician’ position in their organisation and, like the Oiler and Greaser long used to lubricate equipment and stop bearing failures, they get the ‘condition monitoring man’ out amongst the equipment looking for tell-tale signs of coming failure. Such a person will save you a great deal of lost production and frustration.
It is not necessary to spend vast amounts of money on oil analysis programs, thermography cameras, state of the art vibration analysis equipment, ultrasonic listening devices and the like. It is wise to use such technologies selectively when accuracy of results is critical or you need a long warning time to plan and prepare rectification for an item. But you can do a great deal of condition monitoring of mechanical equipment accurately enough yourself with a laser gun to tell temperature, an automotive stethoscope to hear noise, a low-cost bearing vibration detector to note change in bearing vibration, laboratory filter paper to separate debris in oil and a magnifying glass and magnet to check if the debris has iron (ferrous), plus using your own five senses.
When you need expert help for more accurate results, or a measured opinion on the implications to continued operation, or the equipment is particularly critical to your business and you do not have the necessary expertise and skills in-house, sub-contract those specialities in at the time.
Condition Based Maintenance Strategy
With around 80% of equipment failures being totally unpredictable based on the equipment’s age alone, you must have an on-condition maintenance strategy to deal with them.
The around 20% usage or time-based repetitive failures are addressed by doing preventative maintenance and scheduled replacement maintenance well before failure can occur. But non-age related failures cannot be addressed by timed renewal-based maintenance strategies, they require different solutions.
If you apply scheduled renewal based maintenance strategies to non-age related condition failures you will change-out items that still have a long life ahead of them and so waste your money, time and effort unnecessarily.
With time-random failures the simplest (but not the only) management strategy to use is to inspect your equipment and look for evidence of degraded conditions. You can use a continuous means of monitoring condition by using your process computers to trend an equipment’s performance graphically (e.g. power use verses throughput, flow verses pressure, etc), or you can introduce periodic inspections of equipment condition through observation and data measurement (e.g. lubrication sampling, temperature measurement, etc).
If condition monitoring is based on timed inspections, you must set the time periods at a frequency that will let you spot the change well before the impending failure. Figure 3 shows a frequency inspection period that will detect the degrading performance well before the failure. The rule of thumb is to set the condition inspection frequency one quarter the width of the P-F period. This gives your three inspection points before failure. The second point lets you confirm the that the first point is correct and not a random error. Once you are certain the item is degrading you plan for its replacement or repair.
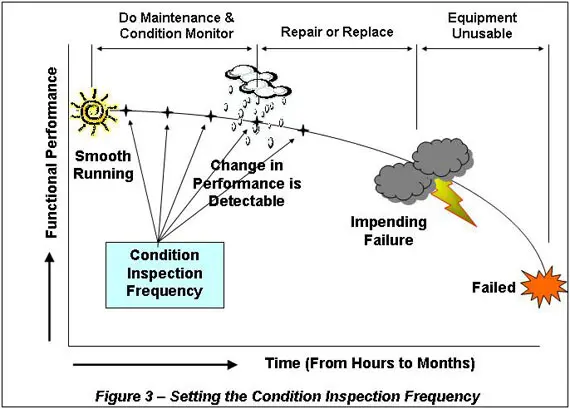
Having discovered the start of a failure you can prepare for its repair, or put into place strategies and make changes in its use, to extend the time to failure.
But doing condition based maintenance will only marginally reduce your maintenance costs. The main thing condition monitoring does for you is to tell you that you have a problem in time to deal with it in a low cost way. It does not stop the problem!
There is one more step that you must now do to drastically reduce your maintenance costs. You must remove the failure mode. Having discovered a cause of failure through condition monitoring, you must now get rid of it, or else it can randomly occur at anytime in the future after it is repaired. Only by removing failure modes will you significantly reduce your future maintenance. In addition to having a way to find the potential failure point you also need a business process that finds and removes the cause of random failures. Random failures are stress induced by specific acts and events. Unless you remove the cause of the incident it will happen again and again, costing you money, time and effort at every occurance. When you introduce predictive maintenance into a company you also need to introduce root cause failure removal as part of the maintenance reduction strategy.
Please click this link if you want to read more about defect elimination strategy.
Unfortunately there are some serious traps in using condition based maintenance that will affect your maintenance delivery and performance. Using condition maintenance can cause you to become a reactive organisation if you decide to rectify problems only after detecting impending failure. Many times it is economically more sensible simply to use time based maintenance and not care about condition because it is the more cost effective option in the circumstances. You can read more about the dangers of misunderstood use of condition monitoring in the PDF articles Don’t Waste Your Time and Money with Condition Monitoring and A Common Misunderstanding about Reliability Centered Maintenance.
My best regards to you,
Mike Sondalini
Managing Director
Lifetime Reliability Solutions HQ

Leave a Reply