
Submitted to ASQC Reliability Review, Nov. 1996
A client wanted to compare the Kaplan-Meier (nonparametric maximum likelihood) estimators of the reliabilities of the old and new products. That is, he wanted me to test reliability functions, Ho: R1(t)=R2(t) for all nonnegative t vs. Ha: R1(t)≠R2(t) for some nonnegative t.
Because I’m lazy and fixed in my ways and because I thought it would be easier to explain, I chose the Kolmgorov-Smirnov (K-S) test [Gnendenko]. It’s convenient, practically every statistics text has the tables, and I can program tables and the test statistic easily. The test uses the maximum absolute difference between the Kaplan-Meier estimates of the two reliability functions. Reject Ho if maximum absolute difference, Dmn=max|R1(t)-R2(t)| exceeds a critical value, where m and n are the two sample sizes.
Programming the test requires programming the doubly infinite series ∑[(-1)k Exp[-2(kz)2]. This is the asymptotic formula for P[Sqrt(mn/(m+n))Dmn<z] as m and n go to infinity. Fortunately, terms of the infinite series converge fast so I only programmed 20 positive and negative [summands]. The Excel spreadsheet on a PC limits accuracy due to overflow, especially exponentials, so there’s no reason to include too many summands. Excel blows up Exp(710) but not Exp(709)=8.2E+307. You might get differences of exponentials greater than those, but the cells don’t print the values.
THE K-S TEST DOESN’T APPLY TO CENSORED DATA!
I had difficulty deciding sample size because only about 30% of the newer product had failed and about 60% of the older had failed. I knew I couldn’t test beyond the minimum of the oldest failure in either sample, min[max(X(i, 1)),max(X(i, 2)] where X(i, j) is the time to failure of the i-th failure in the j-th sample. To extend the test beyond observed failures is like the sound of one hand clapping. Unfortunately (or perhaps fortunately) in reliability you seldom have complete failure samples.
Finally it dawned on me that the K-S test is for complete samples, neither censored nor truncated. I grabbed my text [Gnedenko], but Gnedenko demurely declined to derive the asymptotic distribution of the test statistic. He said it was too advanced. Fortunately I found a modified K-S test for censored data in [Gnendenko et al.]. That bailed me out of the immediate problem, but references in Gnendenko et al. were all in Russian. Nevertheless, I programmed the modification and satisfied the client. The two distributions had less than 24% probability of being the same over the support of the first 30% of failures.
The asymptotic distribution of Dmn is similar to that for the uncensored K-S, an infinite series of the same exponential functions multiplied by normal cumulative distribution functions. I implemented it in Excel. Fortunately it converges fast. The modified K-S is a function of the smaller of the two fractions failed in the two samples, theta=r/m=s/n. The formula is P[Sqrt(mn/(m+n))Dmn(theta)<z] =
N(0,1,a)-N(0,1,-a)+2∑ [(-1)kExp[-2(kz)2](N(0, 1, a(k))-N(0, 1, -a(k))) from k = 1,2,…
where a=z/Sqrt(theta(1-theta)), a(k)=(1+k(1-theta))z/Sqrt(theta*(1-theta)), and N(mean, variance, a) is the cumulative normal distribution function evaluated at the value a.
PRODUCT COMPARISON
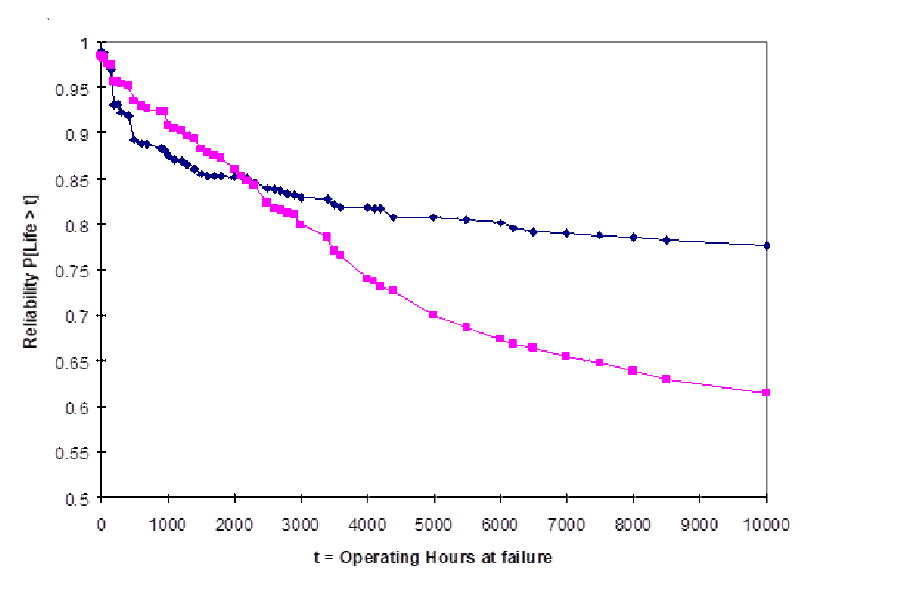
Do old and new products have same field reliability? If so we can combine data sets, we can use the older products’ reliability to extrapolate the younger. The test statistic was 0.0508 at 3500 hours. The sample sizes were 307 and 527. The probability of the null hypothesis, getting that large a test statistic with those sample sizes when they really have the same reliability up to 3600 hours, is 0.30 using the K-S test and 0.24 using the correct, modified K-S test. The incorrect test leaves me on the fence, but the correct test encourages me to conclude the products have different field reliabilities.
This is not a test of the hypothesis that updating has no effect on product reliability. You would have to test many products through several generations to assure yourself that several generations of the same product have the same reliability.
DOES FIELD RELIABILITY EQUAL LIFE TEST RELIABILITY?
I need to test whether field reliability and life test reliability are the same. Naturally operating hours measures life test reliability, because testing was done 24 hours per day every day. Calendar time measures field reliability representing whatever operating hours users felt. It’s subtle, but the field reliability is actually conditional on age-at-failure being less than or equal to the oldest product in the field. (Otherwise, the failure wouldn’t have been observed yet.) We’ll deal with that later. Meanwhile assume you have enough sample data on operating hours per calendar month to estimate its distribution. Ideally you have enough to estimate the distribution conditional on age-at-failure for all ages up to the oldest in captivity. But usually you don’t. So you operate under the assumption that the distribution is the same for all users. That’s still better than assuming every user operates the same hours per calendar time interval.
CAUTION NEUROHAZARD, CALCULUS AHEAD
This is the mathematical explanation of the transformation to convert the field reliability estimate in calendar time to field reliability in operating hours as follows. Let X and Y represent calendar months and operating hours to return. The objective is to estimate the pdf (probability density function) f(y) for all nonnegative y. (All f(.) are discrete pdf estimates with probability at observed return times.) Compute the joint probability density function f(x, y) = f(x)f(y|x). Here f(y|x) is the conditional pdf of operating hours at return given x is calendar age at failure. Sum f(x, y) over x to get f(y) for all nonnegative y<10,000. This gives f(y) the pdf of power supply time-to-return in operating hours up to 10,000 hours from which I computed reliability and failure rate functions in terms of operating hours at return.
CONDITION AND UNCONDITION ON CONVERSION FACTOR
Now you have two empirical or Kaplan-Meier distributions with the same time scale. So why can’t you apply the K-S test as modified [Gnendenko et al.]? Transforming one reliability function to operating hours using an estimated distribution induces statistical uncertainty.
Assuming every product was used the same operating hours per calendar time unit makes the conversion of field reliability to operating hours a one-to-one conversion. Then the modified K-S test can be used as is. Imagine doing it for every observed failure time in the field reliability data set. Assuming the observed failure times are independent and identically distributed, then each K-S test result is equally probable. I compute p-values of test statistics, so the final p-value of the test is the average.
WHAT IF YOU DON’T USE THE EMPIRICAL DISTRIBUTION?
I often compute the nonparametric maximum likelihood and least squares reliability estimators from ships and returns data [George]. These are not the same as empirical distributions or Kaplan-Meier estimators, because data are grouped into time intervals and because data aren’t times to failures. Fortunately, they are population, not sample, statistics, so the only uncertainty in the estimates is due to random censorship.
The modified K-S test applies to Kaplan-Meier estimators, not estimators from ships and returns data. What is the asymptotic distribution of the test statistic, the maximum difference between two reliability functions estimated from grouped ships and returns data? Is the modification in [Gnendenko et al.] still appropriate? Is only power affected, not P[type I error]? If anyone wants to work on this problem, I’ll send references. The reference by Nikiforov appears to derive the asymptotic distribution of the K-S test statistic [Nikiforov Subroutine GSMIRN]. It has a robust program for the K-S test statistic, but not for the modification [Gnendenko et al.].
Send reliability functions, sample sizes, and numbers of failures if you have sample times-to-failures, and I’ll estimate reliabilities and test whether they differ. Send ships and returns data, and I’ll do the same. I’ll test Ho for each pair and report P[Type I error] = P[Reject Ho|Ho true].
REFERENCES
Edward L. Kaplan and Paul Meier, “Nonparametric Estimation from Incomplete Observations,” J. Am. Statist. Assn., Vol. 53, pp. 457-481, 1958
B. V. Gnedenko, The Theory of Probability, Chelsea Publishing, New York, 1962
B. V. Gnedenko, Yu. K. Belyayev, and A. D. Solovyev, Mathematical Methods of Reliability Theory, Academic Press, New York, pp. 274-276, 1969
George, L. L., “Estimate Reliability Functions Without Life Data,” ASQC Reliability Review, Vol. 13, pp. 21-26, March 1993
A. M. Nikiforov, “Algorithm AS288, Exact Smirnov Two-sample Tests for Arbitrary Distributions, Appl. Statist., Vol. 43, No. 1, pp. 265-284, 1994, “Subroutine GSMIRN,” statlib@lib.stat.cmu.edu
REFERENCES FOUND AFTER WRITING THE 1996 ARTICLE
T. R. Fleming, Judith R. O’Fallon, Peter C. O’Brien and David P. Harrington, “Modified Kolmogorov-Smirnov test procedure with application to arbitrarily right-censored data,” Biometrics, Vol. 36, pp. 607-625, Dec. 1980
J.A. Koziol and P. Byar, “Percentage Points of the Asymptotic Distributions of One and Two Sample K-S statistics for Truncated or Censored Data,” Technometrics, Vol. 17 No. 4, pp. 507-510, 1975
K. Langohr, M. Besalú, M. Francisco, G. Gómez, “KScens, Kolmogorov-Smirnov test for complete and right-censored data,” R-package, [Parametric goodness of fit]
Donald R. Barr and Teddy Davidson, “A Parametric Kolmgorov-Smirnov Test for Censored Samples”, Technometrics, Vol. 15, No. 4, pp. 739-787, Nov. 1973

Thanks to Fred for re-publishing old ASQC Reliability Review articles! They are nowhere on the Internet, and there’s no trace of Reliability Review tables of contents. The articles may be old, but they may still be needed. ASQ has given permission for re-publication.