In this week’s edition, I introduce you to the concept of small multiples, and, more importantly, how to make them in R. This is one of those really low effort-super high return kind of features of R that can make you look like a rock star of data visualization. So, without further ado, let’s jump right into it!
You can download the script here if you want to follow along.
We’ll continue working with the dataset we called bond_strength_long from last week after we had transformed it into a tidy format.
As you remember, in last week’s edition we used a technique called stratification to plot the data, and we saw that stratifying the data by a specific variable, in our case by manufacturing line, can reveal additional insight. Stratification is one of those super simple graphical techniques that can reveal differences and provide basis for further analysis. However, in order to truly start to characterize the performance of physical systems such as manufacturing equipment, we often need to take it one step further and go beyond simply stratifying by one variable.

Cyclical behavior, that is observing consecutive machine cycles, can reveal a lot more information and clues than just stratifying by one variable. There’s a lot more to how to put this into perspective, but I will save that explanation for a later edition. For now, let’s just focus on plotting the data in terms of machine cycles.
The bond strength characterization study involved collecting pieces from three consecutive machine cycles from each of the five lines at three different times. The good thing is that machine cycle information has already been captured as a variable named Cycle (we created it just beofe converting the dataset into a long format). At this point, we just need to find a way to visualize it then. Since cyclical data has a time element to it, what we want to do is plot the three consecutive cycles in a line plot, so we’ll be using the geom_line() function instead of geom_point(). So, let’s see what happens when we run the below code.
# 3. PLOTTING ----
# 3.1 LINE PLOT - FIRST ATTEMPT ----
bond_strength_long %>%
ggplot(aes(Cycle, Bond_Strength)) +
geom_line() +
theme_sherlock()
Well, this doesn’t quite look like what we were expecting to see, and that is because we’ll need to do grouping so that the line is created between cycles 1, 2 and 3 and not within each cycle. This is where using geom_line() can get a little more complicated than using geom_point(), but it’s definitely worth learning as it will pay dividends for you.
OK, let’s give this another shot. This time we’ve added the group argument within aes() and assigned Line to it. What this essentially means is that we are telling ggplot to group the output of every geom by the Line variable. Sound simple, right? Let’s see what the output looks like.
# 3.2 LINE PLOT - SECOND ATTEMPT ----
bond_strength_long %>%
ggplot(aes(Cycle, Bond_Strength, group = Line)) +
geom_line() +
theme_sherlock()
Well, it looks different now, but it still looks much like a piece of art rather than a visual display full of information. That is because even though this time we grouped by the Line variable, there is another variable, Time, that we didn’t account for, so what ggplot ended up doing was grouping by Line and connnecting all observations within each Line, including observations from the three time periods, together into a line plot.
We need to find a way to visually group by two variables. Well, this is where a technique called faceting comes into play!
The Concept of Small Multiples
Since faceting is really codename for small multiples, let’s take a minute to discuss what small multiples are. The term was coined by data visualization pioneer and educator Edward Tufte. In simple terms, small multiples are a data visualization technique where, instead of plotting all observations from a dataset in the same space, observations are grouped and displayed in separate smaller displays using the same axes and scale.
Let’s see how to do just what I explained above. We’ve added the function called facet_wrap() and specificied with the ~ operator (tilde) what variable to facet by. We’ve also added a color argument so observations from each manufacturing line is plotted in a unique color.
# 3.3 LINE PLOT WITH FACET_WRAP() ----
bond_strength_long %>%
ggplot(aes(Cycle, Bond_Strength, group = Line, color = Line)) +
geom_line() +
facet_wrap(~ Time) +
theme_sherlock()
You just created your first small multiples plot using faceting. Very simple yet so very powerful!
Instead of faceting by Time, we could also facet by Line:
bond_strength_long %>%
ggplot(aes(Cycle, Bond_Strength, group = Time, color = Time)) +
geom_line() +
facet_wrap(~ Line, nrow = 1) +
theme_sherlock()
We can also facet by not one but two variables creating a grid-like display. This happens to come in handy in our case since we have two both Line and Time we want to facet by. For faceting by two variables, we need to use the facet_grid()function.
# 3.4 FACET_GRID() ----
bond_strength_long %>%
ggplot(aes(Cycle, Bond_Strength, group = Time, color = Time)) +
geom_line() +
facet_grid(Time ~ Line) +
theme_sherlock() +
labs(title = "Process Characterization Results",
subtitle = "Bond Strength, Cycle by Line by Time")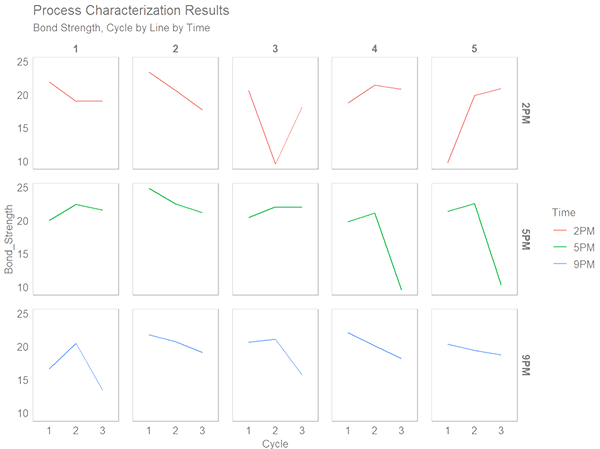
Take a look at the above small multiples plot you just created. Doesn’t it look super clean and easy to read? I think so.
Use this visualization technique and you will likely stand out from your peers.
To recap, this week we learned how to create a small multiples plot using facet_wrap() and facet_grid().

Leave a Reply