Management at Industrial and Manufacturing Sites
Full of new, powerful solutions, the Plant Wellness Way EAM methodology ensures operations and companies get to world class equipment reliability
Let a Plant Wellness Way EAM System-of-Reliability halve your Annual Maintenance Costs
People investigating the Plant Wellness Way enterprise asset management (PWW EAM) methodology want to know exactly what happens when they use it, especially how the analysis and implementation will be done in their own operation. A PWW EAM System-of-Reliability brings you three massive business advantages:
- 1) With PWW EAM you get a methodology designed to get certain world class production asset performance for its users.
- 2) It gets world class plant and equipment reliability in under half the time of other EAM methodologies. That gives you several extra years of world class operating profits.
- 3) It removes both the systematic life cycle risks hidden in your business, and the operational risks when using the operating assets. You get failure-free operating assets that cost so little to use that they make hundreds of percent return on investment all their operating lives.
Prove Plant Wellness Way EAM in-full for yourself on only one complete production asset. That is sufficient experience to see how PWW EAM works, and to decide to use it companywide.

and control system, and all the mechanical items of the pump set. Another example of a complete item of equipment is a large air compressor, with all its structural, mechanical, electrical and control equipment. In the case of an electrical asset, an example is a power transformer, complete with its structural, electrical, and control equipment.
Plant Wellness Way Summary
The Plant Wellness Way is unlike any other enterprise asset management methodology. It is unique in its use of systems engineering, reliability engineering, and operating risk elimination principles to achieve high-reliability, low production cost plant and equipment. The Plant Wellness Way identifies, then removes or prevents operational asset risk. You get the utmost equipment reliability, plant availability, and asset utilization while safely minimizing production unit cost.
PWW produces highly reliable plant and machinery because it specifies exactly how to create and sustain world class equipment health. When machine parts work at least material-of-construction stresses they reach their highest reliability, and the equipment is reliable for its entire service life. By adopting the Plant Wellness Way as your corporate enterprise asset management methodology you ensure that the required means and actions to get utmost reliability from your physical assets are done right first time.
The Boardroom decision to use the Plant Wellness Way as a company’s asset management methodology enables highly effective business processes and reliability practices that create and sustain new operational and maintenance success.
A proprietary six-step IONICS methodology is used in Plant Wellness Way EAM to eliminate life-cycle risks and put guaranteed reliability success into business processes. The best solutions become your standard operating practice, and your people are trained to implement and use them correctly. It is an exhaustive approach that requires you to go deep and thoroughly into an asset’s engineering and operating use. All risks generated throughout the life cycle are identified, and they are either eliminated at their source, or prevented from impacting your production by using effective risk control, life cycle asset management, and profit-centred maintenance strategies.
The Plant Wellness Way enterprise asset management methodology is fully explained in the Industrial and Manufacturing Wellness book. The hardcover book is available from the publisher’s website: https://books.industrialpress.com/9780831135904/industrial-and-manufacturing- wellness/ the ebook version is at https://ebooks.industrialpress.com/product/industrial- manufacturing-wellness.
The book is also at Amazon Books: https://www.amazon.com/Industrial-Manufacturing- Wellness-Mike-Sondalini/dp/0831135905/.
Overview of the Six IONICS Processes for World Class Equipment Reliability
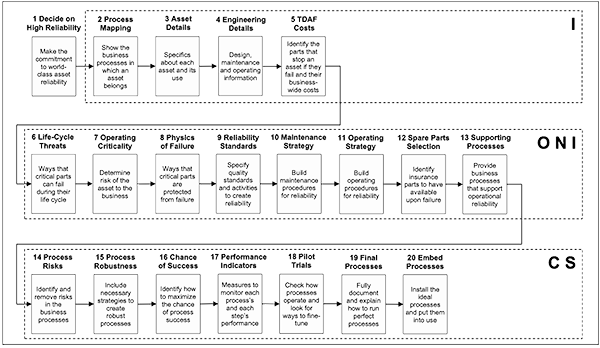
The purpose of each IONICS step is listed below.
- Identify all life cycle risks 4. Introduce risk prevention solutions
- Order risks by importance 5. Control operating processes
- Numerate the risk control options 6. Synthesize new ideas to improve
The IONICS process is summarized in this document as a quick reference for how to use the Plant Wellness Way methodology. With PWW you create a “system of reliability” across your company that maximizes the successful use of all your production assets.
Table 1 lists the necessary tasks and activities required in each IONICS step. It follows the general approach that a licensed PWW consultant adopts when building a PWW EAM system for clients. When fully implemented, PWW gets you the utmost equipment reliability, plant availability, and asset utilization, while safely minimizing your production unit cost.

Below is an overview and brief explanation of the full range of steps performed in a Plant Wellness Way implementation project. They include each asset’s in-depth analysis, the risk elimination strategy selections, development of necessary business process documentation, and the implementation of the new solutions into your operation.
1. Decide That You Want World-Class Reliability
The board and senior executives of an organization publicly state their personal commitment to achieving world-class reliability and allocate sufficient funds and resources to achieve it.
2. Process Map of Business Process to Work Levels
Map the company as it is today from high-level business operations right down to the procedures performed in the workplace. Draw work flows across the page, adding summary procedures below a step and noting all its required outputs above the step. For each output specify its ideal range of quality values.
3. Asset Lifetime Details
Describe each operating asset and understand its required duty and service life.
- Tag or equipment number
- Asset description
- Asset criticality (highest rating from asset criticality step)
- Asset location
- Asset purpose and required operational output(s)
- Installed new or second-hand? If second-hand, where was it used prior to thisoperation?
- Date installed in the operation
- Frequency of use during current service life
- Subassemblies (children)
- Subassemblies’ tag or equipment numbers (if used)
- Subassemblies’ descriptions
- History of failures for this asset
o At the operating site (list failures by date in a spreadsheet)
o Types of failures that similar assets experience in the industry (list in aseparate spreadsheet)
Asset Failure Frequency Distribution
- Create a failure run chart for the asset over its entire service life to date. Whenever possible, identify the cause(s) of each failure event. You may need to look at the operating history in log books and shift logs or the maintenance history in the CMMS and even conduct interviews with knowledgeable operations and maintenance personnel.
- Develop a failure event frequency distribution curve for the asset using the failure history timeline.
- Identify which failure types and/or causes occur too often.
4. Asset Engineering Design, Drawings, Manuals, and Parts Lists
It is necessary that the construction, use, and correct performance of an item of equipment is fully understood at the design engineering level. Gather all of the technical, maintenance, and operational information about the asset, such as equipment manufacturer’s information, manuals, drawings, and so on.
Collect these details for each asset:
- Service duty when in use
- Design data (e.g., maximum/minimum pressures(s), maximum/minimum flow(s),maximum/minimum temperature(s), maximum/minimum hours of operation)
- Operating and maintenance manuals
- General assembly drawings
- All subassemblies
- All parts
- All parts’ materials of construction
5. Identify All Critical Parts and Their TDAF Costs
Identify the parts in an asset whose failure would stop a critical assembly from operating—these are called critical parts. They are often the working parts, or the moving parts, in the asset. They can also be the structural components and/or the fastening components.
When critical parts fail, there can be catastrophic consequences to the business. Determine the business-wide TDAF costs of their failure to see how disastrous a breakdown would be to the organization. Record this information in the Operating Criticality Analysis spreadsheet.
- Identify on the bill of materials parts whose failure would cause adverse production impacts.
- Estimate the TDAF costs for each part’s failure.
6. Critical Part Life-Cycle Threats
When a part can fail, it is necessary to explore what events across its life cycle could happen and become the root causes of a failure.
Answer the Eight Life-Cycle Questions
In the Physics of Failure Factors Analysis spreadsheet (see Chapter 11), answer the eight Life- Cycle Questions for each critical part.
You want to gain a solid understanding of the opportunities and situations in which critical parts can fail and the circumstances that lead to a component’s failure.
For each critical part, identify if it can be failed from the following:
• Early-life failures occurring from situations such as
o Manufacturing error and failure-inducing manufacturing methods o Human error during assembly or rebuild
o Human error during installation
o Human error during commissioning
• Random events, including
o Failure inducing manufacturing process methods o Extreme stress events
o Cumulative stress events
o Acts of God or natural events
• Failures from asset use (e.g., filters blocked, brake pads worn out, etc.)
o Causes of a part’s failure during operation
o Hours of operation, number of times used, and/or production throughput between failure events
Do a Physics of Failure Factors Analysis to identify all of the failures that could happen to each critical part, along with each of its cause mechanisms. In a POFFA, you identify all of the failure mechanisms from throughout a critical part’s life cycle that cause risk of stress or structural harm.
- Use the Physics of Failure Factors guideword list (see Chapter 11) to identify events that could fail microstructures from deformation, fatigue, degradation, or damaging environments.
- Indicate all life-cycle phases during which each failure event cause could happen.
The POFFA is done at this point to prove that there truly are risks throughout your business that can cause your plant and equipment to fail. If a company is to achieve world-class reliability, it must remove all dangers and risks to the reliability of its plant and equipment.
7. Asset Operating Criticality
Conduct an Operational Criticality Analysis to identify the severity of business risk from a failure of each critical part in an asset. Determine Criticality 1 and Criticality 2 values for all critical parts.
Use a separate spreadsheet for each production process used.
- Do risk analysis based on ISO 31000 Risk Management Guidelines or equivalent.
- Calibrate the risk matrix and clarify the location of the low risk level and other levels, including a region of “accepted” risk.
- Ensure that the company’s risk matrix consequence categories are financially equivalent for the various risk event types and properly applies log10-log10 math.
- Expand the risk matrix into at least a 16 x 13 log10-log10 layout. It is preferable to use a fine scale for the axes so that movements in risk can be seen clearly.
- Make an estimate of the frequency of POFFA events occurring using the likelihood scale of the risk matrix.
- Develop an “operating risk window” on the risk matrix from worst possible impact event to least impact event. Consider the range of business impacts from its failure, including safety, financial, environmental, operational, and so on.
o Use TDAF costs of each event in the criticality analysis.
o Include downtime from each event (least to maximum duration).
o Include “acts of God” when such are possible (e.g., lightening, flood, earthquake, tornado, etc.) - Take into consideration the consequential impacts of an asset’s failure o What else stops when the asset fails?
- Would subsequent harm also occur to personnel, environment, next-door sites, and so on?
- What redundancy exists for the asset?
- What is the time needed to supply failed parts once an order is placed?
Subassembly Criticality
Because of the size and complexity of an asset, it may be necessary to investigate its subassemblies separately.
- Repeat the costing for each of the subassemblies (children) when a failure could stop an asset’s operation.
8. Physics of Failure Reliability Strategy Analysis
Complete a Physics of Failure Reliability Strategy Analysis for those parts that carry unacceptable operating risk from failure. The aim is to prevent all risk and defect creation events from occurring throughout a component’s lifetime. Select effective risk controls and mitigations for each failure mechanism using the Physics of Failure Reliability Strategy selection spreadsheet (included in the spreadsheets accompanying this book).
- Complete the asset details in the Physics of Failure Reliability Strategy spreadsheet.
- Transfer all POFFA critical parts and their cause mechanisms into the spreadsheet.
- Determine suitable life-cycle strategies to eliminate or prevent each mechanismfrom arising.
- Indicate all of the life-cycle phases during which the risk mitigations are to be used.
9. Specify Reliability Standards by Equipment Part
Identifying what can be done to achieve maximum reliability for a machinery part’s operating life requires defining precision zones of outstandingly reliable operation for each critical component using the precision maintenance criteria listed in Table 2. To tailor probability in your favor set 3T (target, tolerance, test) quality values for each criterion listed. Extend the list to include all engineering, maintenance, and operating criteria needed to address the POFFA mechanisms. Although this list applies to mechanical equipment, the setting of quality requirements is a universal principle that applies to all other types of physical assets and their components, including structural, civil, electrical, and electronic items. For all assets you need to set and determine all the quality values that bring them long, trouble-free service lives
| 1 | Accurate fit and tolerance at operating temperature | Target: Tolerance: Test: |
| 2 | Impeccably clean, contaminate-free lubricant for the entire lifetime | Target: Tolerance: Test: |
| 3 | Distortion-free equipment for the entire lifetime | Target: Tolerance: Test: |
| 4 | Shafts, couplings, and bearings running true to center | Target: Tolerance: Test: |
| 5 | Forces and loads into rigid mounts and supports | Target: Tolerance: Test: |
| 6 | Collinear alignment of shafts at operating temperature | Target: Tolerance: Test: |
| 7 | High-quality balancing of rotating parts | Target: Tolerance: Test: |
| 8 | Low total machine vibration | Target: Tolerance: Test: |
| 9 | Correct torques and tensions in all components | Target: Tolerance: Test: |
| 10 | Correct tools in the condition to do the task precisely | Target: Tolerance: Test: |
| 11 | Only in-specification parts | Target: Tolerance: Test: |
You want a critical part to always remain within its reliability precision zone by selecting the appropriate quality standards for engineering, maintenance, and operating activities and practices. The standards let you monitor actual behavior during equipment manufacture, installation and use to ensure that a component suffers the least stress possible in every situation across its lifetime.
- A target value (ideally, this is world-class performance, or at least a magnitude better performance than average performance).
- A tolerance range (for physical assets the minimum value is that specified by the original equipment manufacturer in its manuals).
- A challenging “stretch” value set between minimum and world-class performance dividing the tolerance range into three clearly identifiable zones.
In the case of dimensions, instead of specifying each part’s specific tolerance values, you can use International Tolerance Grades, which automatically allow for changes in component size and distance.
The activities needed to achieve and sustain the quality standards that maximize the reliability of a critical part become the operating, maintenance, and reliability strategies adopted for the component during its lifetime. The sum of an equipment’s parts reliability strategies become the asset’s life-cycle management strategy. All strategies and how they are to be achieved will be fully explained in the asset’s engineering, operating, maintenance, and reliability procedures and relevant documents.
Reliability Growth Cause Analysis
This technique is a detailed reliability strategy selection, analysis and cost–benefit justification for the tasks used to make a part survive to maximum service life.
10. Maintenance and Installation Parts Deformation Management
The requirements are to have all equipment parts in their least-stress, full-health condition during operation and to sustain those conditions throughout the equipment’s service life. The life-cycle microstructure risks for each critical part identified in the Physics of Failure Reliability Strategy spreadsheet are now addressed with truly useful maintenance activities. Where statutory laws and regulations apply to an asset, such as cranes, pressure vessels, lifts, and so on, include the necessary maintenance requirements in an additional column in the spreadsheet.
- For each critical part, identify
- Necessary health conditions for the part (e.g., precision tolerance range, temperature range, moisture/humidity range, etc.); the information identified in response to the list of 3T quality parameters required in Table A.1 will satisfy this requirement
- Necessary health conditions of neighboring parts in contact (e.g., surface finish, temperature range, etc.)
- Likelihood that the health conditions will be achieved during installation
- Likelihood that the health conditions will be sustained during operation
- Installation and maintenance opportunities that could arise to cause deformation (e.g., installation during construction, overhaul during service life, major failure requiring rebuild, etc.)
- Frequency with which the identified installation and maintenance opportunities for deformation will arise
- Check the Physics of Failure guidewords to confirm that all situations are identified and covered by a suitable and effective strategy for the part and for its neighbors.
Develop Maintenance Procedures
For each critical part, put the required controls for every cause of deformation into a written ACE 3T maintenance procedure to create a component with low stress in a healthy environment.
In time, a library of procedures for component health will accumulate that can be used repeatedly in future for assets where critical parts suffer the same situations and threats of failure.
Identify Work-Around upon Failure
When there are means to minimize the production impact of an asset’s failure, list and explain the option(s), such as redundancy, hiring of mobile equipment, transfer of production to another line, and so on.
11. Operating Strategy Parts Degradation Management
The requirement is to have all equipment critical parts in their least-stress condition during operation and to sustain those conditions throughout the equipment’s service life. Develop standards for operation of plant and equipment to ensure workplace safety and the long service life of parts in the Physics of Failure Reliability Strategy spreadsheet.
- For each critical part, address
- Necessary operating conditions for the part (e.g., operating pressure range, operating temperature range, operating moisture/humidity range, etc.)
- Likelihood that the operating conditions will always be achieved
- Likelihood that the operating conditions will be sustained during service life o Operating opportunities that could rise to cause degradation (e.g., change-overs, process disruptions, poor raw material, contamination, etc.)
- Frequency with which the identified operating opportunities for degradation will arise
- Check the Physics of Failure guidewords to confirm that all situations are identified and covered by a suitable and effective strategy.
Develop Operating Procedures
For each critical part, put the required controls needed for each cause of degradation into a written ACE 3T operating procedure to create a component with low stress in a healthy environment.
Identify Work-Around upon Failure
When there are means to minimize the production impact of an asset’s failure, list and explain the options(s), such as redundancy, hiring of mobile equipment, transfer of production to another line, and so on.
12. Spares Selection by Part
The spare parts that must be speedily available are chosen based on the operational risk from a part’s failure. Develop answers for each critical part in the Physics of Failure Reliability Strategy spreadsheet.
- Determine the TDAF cost consequence of a critical part’s failure, allowing for any work-around available to the organization
- Determine the frequency of a critical part’s failure:
- In the operation
- In the industry
- Allow time for the supplier to deliver replacement parts when ordered
- Determine the resulting risk reduction if a part is available in a timely manner.
13. Supporting Business Processes
Use the Stress-to-Process Model to identify who must be involved throughout the organization to ensure the integrity and security of the asset and its critical parts for both degradation management and deformation management during the following:
- Design selection
- Manufacturing
- Procurement and delivery
- Initial installation
- Throughout its service life
- Decommissioning and disposal
Set the responsibilities for doing all Physics of Failure Reliability Strategy actions. This requires identifying who will do the work of delivering the reliability strategy. For each critical part’s reliability strategy, specify the following:
- Skill set and minimum competence required
- Role(s) or function(s) that will do the work
- Organizational department owning the work
Identify all of the documents that contain each of the life-cycle strategies, actions, and monitoring (e.g., procedure, work instruction, duty statement, etc.) so that ownership of responsibilities is clearly allocated. The same reliability creation information can be required to reside in more than one document.
Design and Operations Costs Totally Optimized Risk (DOCTOR)
The DOCTOR business risk assessment is to be immediately introduced into all capital projects and plant change projects.
14. Risk Analysis of Supporting Business Processes
Check to see what risk situations, scenarios, and events could arise in all business processes that impact the life cycle to cause the failure of any critical parts in an asset.
Put the process steps across the top of a spreadsheet, and for each step, do a risk analysis focused on how a step could cause plant and equipment parts to fail. In the analysis, address the risks in each business process and its individual steps affecting the following:
- A complete asset
- Subassemblies
- Parts and components
- Work procedures
15. Build Process Robustness
Once potential problems are identified, Three-Factor Risk Analysis strategies are selected to substantially reduce the risks and mapped onto a risk matrix to confirm that the risk reduction will occur. All means to make processes antifragile and robust are developed and incorporated into business process and procedures.
Consider applying the following techniques:
- Consequence reduction strategies
- Opportunity reduction strategies
- Uncertainty reduction strategies
- Improvement of component robustness and reliability
- Parallel tasks (application of the Carpenter’s Creed, “measure twice, cut once”)
- 3T (Target-Tolerance-Test) error-proof activities
- Mistake-proof techniques included in the process design
16. Chance of Success Analysis for Processes
Once a process is designed, you can simulate and test how well it will work. A business process has risks of failure in each process step. Identify what can prevent a process step from being completed correctly. Possible problems that arise in each process step are recorded, and a value of the chance of a problem’s occurrence is determined from historical data. Processes that have an unacceptable chance of not working well are weak processes and must be redesigned to be much more effective.
For each process develop a flowchart showing all its steps across the top of a spreadsheet. For the process,
- Explain and define the purpose of each step
- Describe the procedure for doing the step
- Specify the correct step inputs using 3T format o Specify the correct step output using 3T format
- Identify problems and weaknesses in each process step through the use of risk analysis
- Make probability estimates of each existing process step’s low and high chance of success
- Calculate the whole current process’s low and high chance of success
- Propose how to resolve unacceptably weak process steps
- Introduce 3T controls
- Introduce redundancies
- Introduce effective technology
- Redesign the step with a more effective procedure
- Make low and high probability estimates of each redesigned process step’s chance of success
- Calculate the redesigned process’s low and high chance of success
- Continue developing solutions for weak processes until the low chance of success for the whole process is adequately high
17. Performance Indicators
The effectiveness of a process is seen in its results. Develop measures to monitor your processes and workplace activities. Embed the data collection and report generation into relevant procedures.
- Establish process step Performance Indicators for self-monitoring by the step “owner”
- Monitor inputs
- Monitor outputs
- Establish frequency distribution curves of step monitoring PIs
- Establish process outcome KPIs for regular senior management monitoring
- Establish frequency distribution curves of senior management KPIs
- Monitor performance with a useful mix of
- Leading indicators
- Lagging indicators
- Process distribution curves
- Cascade measures across departments and roles if necessary to understand the process behavior
To keep moving a company forward, keep moving the required performance ever higher toward the pinnacle of excellence by making the ACE 3T standards ever more demanding.
18. Pilot Test Trials
A new process is designed to what seems like a suitable degree of outcome certainty. Before changing an entire business to the new process, it needs to be tested in the workplace to be sure that it is effective. A Change to Win project can be used to involve the users of the new process and get their input and buy-in. The learning from the trial is put back into the process design to make changes and refinements that improve its chance of success when implemented in the company.
19. Document the Final Process Designs
Specify and define the complete process and all of its procedures in total detail to ensure process control and capability.
For each process,
- Map each level, from top overview down to the shop floor, in the detail needed to get the desired success rate.
- Establish procedures, including detailed instructions when risks in process steps justify the need to be meticulous.
- Incorporate 3T quality assurance.
- Identify each process step “owner” who has ultimate responsibility to do the step correctly.
- Identify each process step “buddy” when people are put in parallel for better process reliability.
20. Embed the Final Processes
Prior to putting the final process design into use, everyone impacted by the new process needs appropriate levels of training and practice. The people working in the new process need to be competent to do their new roles before the process is implemented. Becoming proficient requires both the education and understanding of what is to be done, as well as the practical skills to ably do the role.
The final action is to run the process in its entirety and monitor whether individual steps are delivering the required performance results. When problems arise, look at the step distributions to identify the causes of excessive variation and fix the process design.
All the greatest success to you, and to your organization,
Mike Sondalini

Leave a Reply