
Many industries are using this formula to manage Multi-Million-dollar assets:
MTBF = Total Operating time ÷ Number of failures
Simple. Easy. Dangerously incomplete.
The problem?
Simple arithmetic MTBF assumes failures are Random and Constant. It treats asset health as Static.
But real-life industrial assets are not static. Failure rates are not constant.
Assets age. Lubricants degrade. Corrosion accelerates. Fatigue accumulates. Failure rates begin changing long before catastrophic breakdown occurs.
The infographic below for illustration purposes of the flaw:
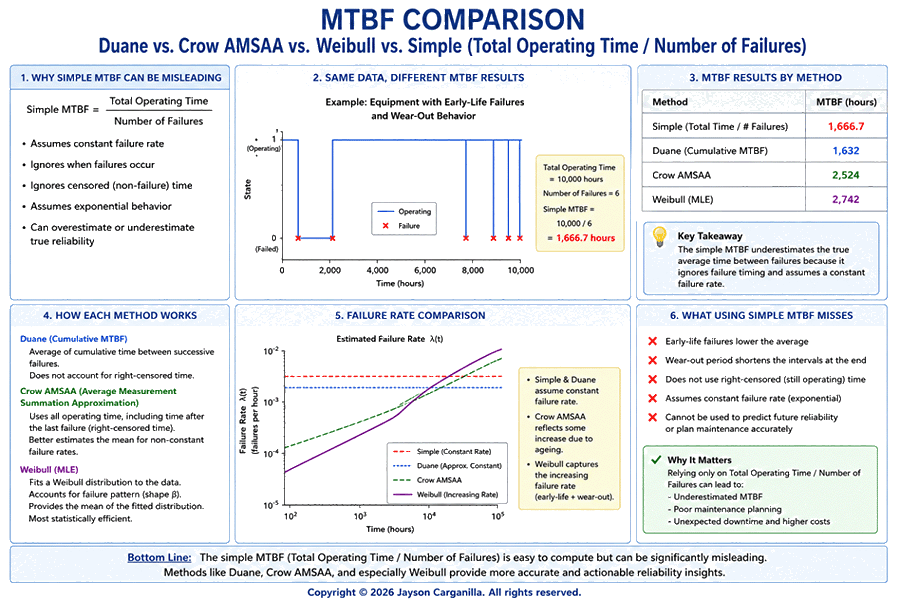
Look at the breakdown from the same 10,000-hour operating time with 6 failures:
- Simple MTBF: 1,666.7 hours
- Duane (Cumulative MTBF): 1,632 hours
- Crow-AMSAA: 2,524 hours
- Weibull (MLE): 2,742 hours
Now, multiply this to a fleet of equipment, hundreds of equipment, that is a massive delta in:
- maintenance strategy
- risk exposure
- production planning
- operational availability
- economic outcome
Why is Simple MTBF so inaccurate here?
Because basic arithmetic completely ignores the critical context of failure data:
- It ignores right-censored operating time The asset continues accumulating valuable healthy operating hours after the last failure, but arithmetic MTBF discards this information completely.
- It ignores failure timing Early-life failures, stable operation, and wear-out behavior are all averaged together as if they are identical.
- It assumes constant failure rate behavior even when degradation is clearly accelerating, simple MTBF forces the asset into a flat exponential assumption.
When organizations rely solely on arithmetic averages, they unknowingly create massive hidden economic losses:
- Over-maintaining assets by having short intervals instead of longer intervals — creating maintenance-induced failures
- Replacing components too early — wasting remaining useful life
- Performing unnecessary shutdowns — sacrificing production time
- Consuming excess labor
- Consuming and Storing massive spare parts inventories
- Missing degradation trends — missing the early-stage degradation trends.
Two assets can have the exact same simple MTBF but entirely opposite risk profiles.
One may be completely stable. The other may already be entering rapid, high-risk wear-out.
Arithmetic MTBF cannot distinguish the difference.
This is where advanced Reliability Engineering becomes the natural evolution of asset management through probabilistic and data-driven methodologies:
- Weibull Analysis MLE
- Crow-AMSAA & Reliability Growth Analysis (RGA)
- RBD/RAM Modeling
- Monte Carlo Simulation
- Predictive Maintenance
- Oil Analysis
- Advanced Condition Monitoring
- Corrosion Monitoring
These approaches allow forward-thinking organizations to move beyond rigid reactive metrics and transition toward probabilistic asset management.
The objective is never “more maintenance.”
The objective is:
- Better asset decisions
- Predictable asset health
- Maximum production uptime
- Higher operational availability
- Lower lifecycle costs
- Optimized maintenance intervals
- Superior economic outcomes
The future of Asset Management is not based on simple arithmetic averages.
Modern industrial assets justify a much higher level of reliability sophistication because the economic consequences of downtime are simply too high.
The future belongs to organizations that manage assets by understanding:
- Actual failure behavior
- Statistical uncertainty
- Degradation trends
- Operational risk
- Probabilistic decision-making
Reliability is no longer just an engineering KPI.
Reliability is a business profitability engine.

Leave a Reply