
This article is adapted from Chapter 6 of my book, Measuring Manufacturing Effectiveness.
The book examines how manufacturing organizations define and use performance metrics, and how those measurement choices influence decisions, priorities, and behavior on the shop floor and in management. While the chapters are organized as a cohesive framework, each one is written to address a specific aspect of manufacturing effectiveness and can be read independently.
Chapter 6 focuses on a critical but often oversimplified topic: downtime.
Most organizations track downtime in some form, but far fewer distinguish meaningfully between how often downtime occurs and how long it lasts. These two dimensions — frequency and duration — are frequently combined, averaged, or summarized in ways that mask important operational realities.
This chapter explores why separating downtime frequency from downtime duration matters, how each dimension points to different underlying causes, and how failing to distinguish between them can lead to ineffective or misdirected improvement efforts.
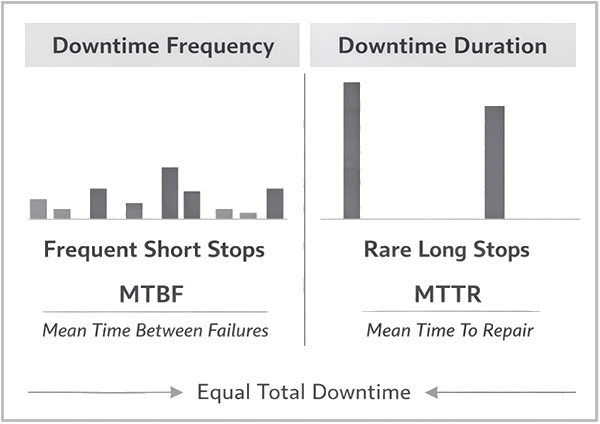
Downtime Frequency and Duration
Availability depends jointly on interruption frequency and recovery duration. These dimensions describe different operational behaviors.
- Frequent short interruptions indicate lower MTBF and lower MTTR
- Infrequent long interruptions indicate higher MTBF and higher MTTR
Both patterns may produce similar total downtime while creating markedly different production environments. Availability alone does not distinguish between these behaviors; MTBF and MTTR together provide the necessary context.
Frequent Short Interruptions
With a lower MTBF and MTTR, production is repeatedly interrupted and restarted. Individual events are brief, but cumulative disruption is significant.
This pattern is often normalized at the operator level. Interruptions may be described as resets, nuisance stops, or momentary faults, and without an automated data collection system, are inconsistently recorded. As a result, reported downtime may understate the true impact on production flow and stability.
Operational consequences of frequent short interruptions include:
- Fragmented production
- Repeated ramp-up losses
- Increased operator workload
- Erosion of standard work
- Increased susceptibility to quality instability
Although recovery is rapid, the production system rarely operates in a sustained steady state.
Infrequent Long Interruptions
With a higher MTBF and MTTR, failures are rare but highly disruptive. These events are typically visible to supervision and management and trigger formal response processes.
Despite their severity, infrequent long interruptions are often easier to plan around. Production schedules can be adjusted, resources reassigned, and corrective actions documented. These events are almost always captured accurately in downtime reporting.
Figure 5 illustrates the key differences between the interruption types.
Equal Downtime, Different Operational Reality
Systems with equal total downtime can impose very different operational demands.
Frequent interruptions impose continuous cognitive and procedural load on operators and supervisors. Infrequent interruptions impose episodic disruption but allow extended periods of uninterrupted production.
Total downtime does not distinguish between these realities. Downtime behavior does.
Secondary Effects of Downtime Behavior
Downtime behavior influences performance and quality beyond its direct impact on availability.
Frequent interruptions increase the likelihood of:
- Performance loss during repeated ramp-up
- Quality loss during restart and stabilization
- Operator workarounds
- Informal adjustments that bypass standard controls
These effects are often misclassified as performance inefficiency or quality problems, when their origin lies in interruption behavior.
Matching Improvement Strategy to Downtime Behavior
Effective improvement requires alignment between downtime behavior and corrective action.
- Frequent interruptions indicate the need for reliability improvement and robustness
- Long interruptions indicate the need for improved maintainability and recovery capability
Treating all downtime as equivalent leads to misdirected effort and limited improvement.
Availability as a Management Lever
Availability reflects decisions made across design, maintenance strategy, staffing, training, and operational authority. It is not a passive outcome.
In many operations, reducing MTTR yields faster and more predictable gains than attempting to eliminate failures entirely. Incremental reductions in recovery time, applied repeatedly, can recover more production capacity than eliminating infrequent failure modes.
Availability establishes the ceiling for performance and quality. If equipment cannot run when scheduled, downstream improvements have no effective domain.
Key Takeaways
- Availability loss arises from both interruption frequency and recovery duration, which describe fundamentally different operational behaviors.
- Frequent short interruptions and infrequent long interruptions can produce similar total downtime while creating very different production environments.
- Total downtime alone does not capture downtime behavior; MTBF and MTTR together provide the necessary context.
- Frequent interruptions disproportionately disrupt flow, increase ramp-up losses, and elevate risk of performance and quality instability.
- Effective improvement requires matching corrective action to downtime behavior rather than treating all downtime as equivalent.
Understanding how downtime occurs is as important as knowing how much downtime occurs, because behavior and totals together determine its operational impact.
This chapter is part of Measuring Manufacturing Effectiveness, a 12-chapter framework that examines how manufacturing performance metrics are defined, interpreted, and used to guide improvement and decision-making.
The complete book brings these ideas together into a coherent measurement system, supported by figures, equations, and practical examples that place topics like downtime, Availability, Performance, and Quality into a broader operational context.
If you’d like access to the full framework, the book is available on Amazon here:
If you purchase Measuring Manufacturing Effectiveness through this link, it helps support the ongoing work of Accendo Reliability, which has generously hosted this serialized release.
Ray Harkins is the General Manager of Lexington Technologies in Lexington, North Carolina. He earned his Master of Science from Rochester Institute of Technology and his Master of Business Administration from Youngstown State University. He also teaches 60+ quality, engineering, manufacturing, and business-related courses such as Quality Engineering Statistics, Reliability Engineering Statistics, Failure Modes and Effects Analysis (FMEA), and Root Cause Analysis and the 8D Corrective Action Process through the online learning platform, Udemy.

Leave a Reply