
Getting extraordinary equipment reliability
This paper is primarily on understanding how to get extraordinary equipment reliability. The paper explains where equipment failures start in organisations. It clarifies the need to recognise the effect, and to control the influence, of interacting processes across the life cycle. It explains the successful philosophies and practices used in high reliability organisations and it introduces a reliability-causing methodology to help companies find what to do to become high-reliability organisations.
Keywords: equipment reliability, precision maintenance, plant availability, life-cycle, right-first-time, high reliability organisation
Extraordinary equipment reliability is rare. It first requires a solid understanding of how it is achieved. Plus the willingness to expend effort, time and a little money to set-up the necessary precision standards, the business processes and do the required training to achieve the standards. Once you understand what delivers phenomenal plant availability, you can create it in your organisation.
Equipment is first designed as images and words. Designers turn imagination into detailed blueprints, specific material selections and precise written instructions. Parts are gathered together into working assemblies and the assemblies collected together into a machine or equipment. Each part is constrained to work within the physical limits of its materials and to stay within the tolerance of its position. Few designers realise how such demands can turn their dream into an owner’s nightmare.
The designers expect their machine to be used as it was designed to be used. All parts stay within positional tolerance at operating conditions, lubricant is perfectly clean and comfortably meets the duty specification, the stresses and strains on parts stay a factor of safety less than the capability of the selected materials of construction, loads and forces act through the paths designed for them to follow. From the designers perspective there is no reason that the equipment should fail unexpectedly because it was designed to work properly. Yet plant and equipment do fail often. When they do it can cause amazingly huge business-wide losses; even death.
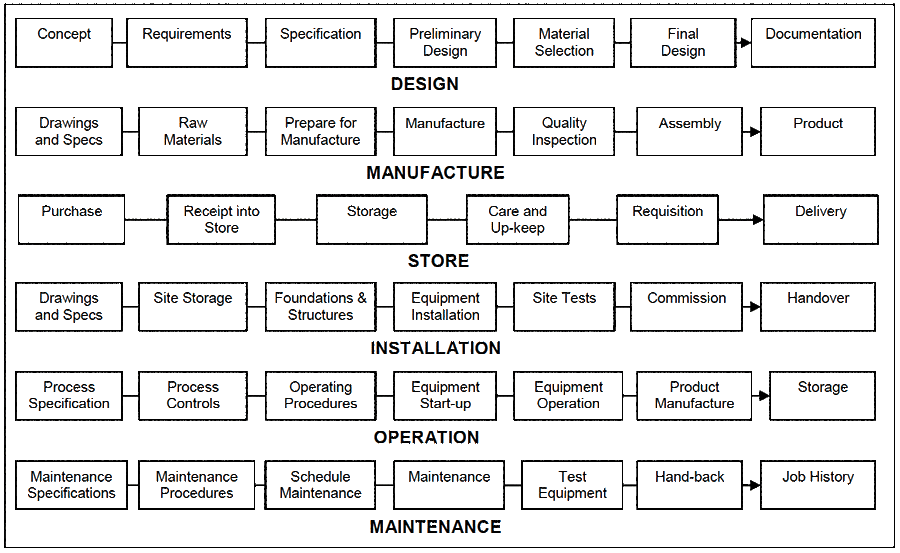
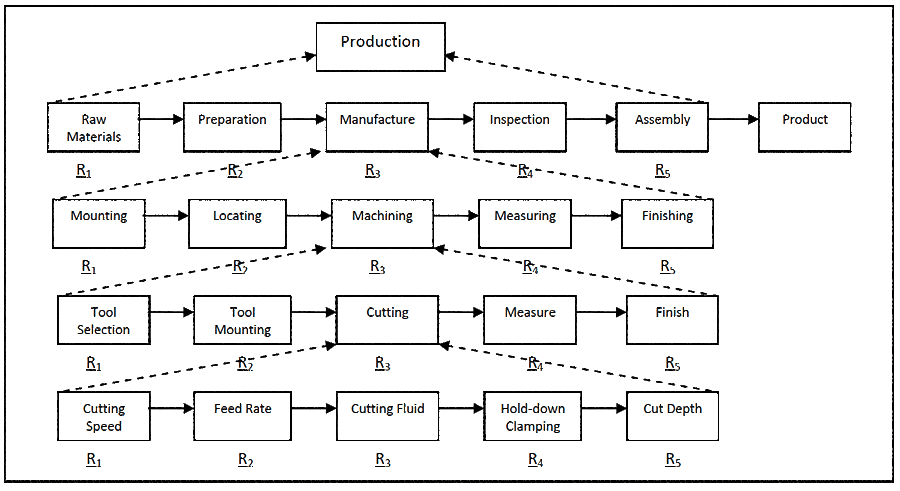
To appreciate what happens to cause equipment to fail you need to view the activities involved in design, manufacture, storage, installation, operation and maintenance as a process. Actually they are a series of processes disjointed from each other. Figure 1 shows summary steps for each of the six processes that affect equipment reliability.
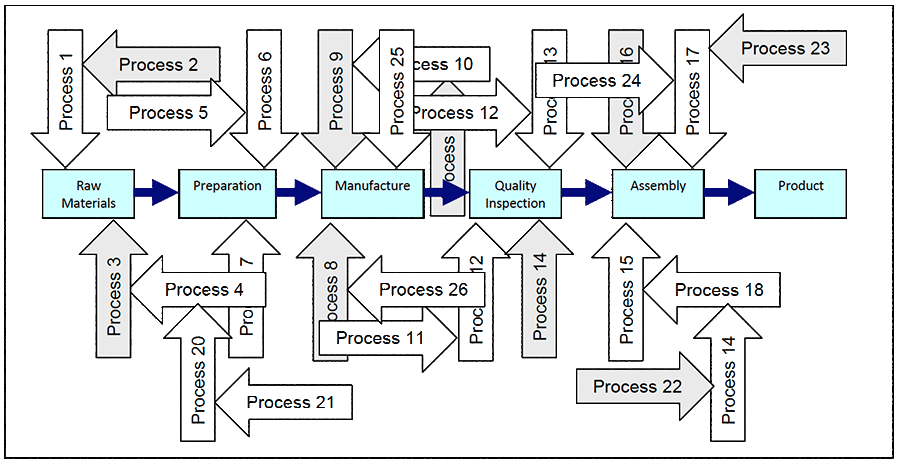
Not obvious is the hidden complexity behind each process and within each step of a process. Figure 2 indicates the hidden complexity in, for example, a manufacturing process. Each step can involve numerous activities and actions requiring many decisions and choices, each done to varying degrees of uncertainty. Each process impacts the performance of others; process after process. It is this random, far-reaching process step variability that introduces defects which cause our equipment failures.
All our business and production processes have similar complexities to Figure 2. They provide many opportunities for small errors, misunderstandings and inconsistencies. These faults and discrepancies accumulate to produce variations outside of the equipment’s design parameters. Equipment parts get stressed and strained beyond design. At some point an overly excessive load, or simply the accumulated fatigue from many loads (the proverbial straw that broke the camel’s back), cause our unexpected equipment failures. If you are to have extraordinarily reliable equipment you will need extraordinary certainty over what happens in the processes that impact your equipment reliability.
/There are literally hundreds and hundreds of opportunities for variation in your organisation. Each variation can be the start of a future problem. To stop failures you need to limit the effect of variation.
It is important to appreciate how very hard it is to get high equipment reliability if you do not know what to do to get it. If you leave reliability to happenstance and good intention you will likely never achieve it against the incredible odds you face. This can be better understood with some simple reliability mathematics.
The Reliability of Processes and Systems
Every business processes, production process, and maintenance process involves a series of tasks and activities. Things are done one after the other in some sort of agreed order. Figure 3 is the simplified manufacturing process with each step having its own level of reliability ‘R’, which is the certainty of producing first-pass product, right-first-time.

Equation 1 is the equation for the reliability of a system of ‘n’ items in series. The items can be parts in a machine or tasks in a job or equipment in a production line. The equation applies to human activity as well as it does to designed equipment.
Rseries= R1 x R2 x R3 x …Rn Eq 1
The reliability of the entire series is the multiplication of the reliabilities of the individual items in the series. Say, for the sake of the example, we assume each step in a process goes right 99 times out of each hundred times it is done. In reliability terms each step is 0.99 reliable each time. By the Motorola 6-Sigma method this represents close to four sigma accuracy and would be an impossibly good performance to replicate consistently unless you followed strict quality controlled conditions. The vast majority of companies aren’t that good.
If there are five steps in the process the series reliability is:
Rseries = 0.99 x 0.99 x 0.99 x 0.99 x 0.99 = (0.99)5 = 0.95
This means the series outcome is wrong five times in a hundred times it is performed. The reliability and certainty of a series falls as the series grows in length. For the same example with a ten step process, the series reliability is 0.90 (10 out of each 100 is wrong), for a twenty step process it falls to 0.82 (18 out of each 100 is wrong). Figure 2 reminds us that every process comprises multiple steps, each step having complex interactions with other processes, and those processes also interact with still more processes. It is not too difficult to imagine process chains of forty steps (67 right in every 100 if each step is 0.99 reliable), and fifty steps (61 right in every 100 for steps 0.99 reliable) in length by the time a job is completed or a part is made.
If we apply the same approach to the typical three sigma organisations in business, where there are seven errors in ever hundred opportunities (i.e. R = 0.93), the reliability of business processes plummets. For a five step process in a 3-sigma company the reliability is:
Rseries = 0.93 x 0.93 x 0.93 x 0.93 x 0.93 = (0.93)5 = 0.70
Now only seventy out of every hundred pass right-first-time, the other thirty are scrap or rework. It quickly gets worse as the number of steps in series increases. If the same calculation was done for a 10-step process, the series reliability would be 0.48, and over half of the outcomes would be wrong.
It is very hard to have high reliability, which is why there are so very few four and five sigma companies and so many two and three sigma companies. Fortunately the problem has an obvious solution. If you want high series reliability with high certainty of the process outcome being right-first-time, you must raise the ‘R’ of each process step.
Control Process Step Variation
The challenge to getting right-first-time process outcomes is the realisation that you must first get each series step accurate. From what may now be wide variations, you must change the process steps to produce variation constrained to within the desired range, and none other. If there are external processes impacting the reliability of a step, like those represented in Figure 2, the accuracy of each step in those processes also may need to be greatly improved. Your purpose is represented in Figure 4, where the left-hand performance must be turned into the right-hand performance.
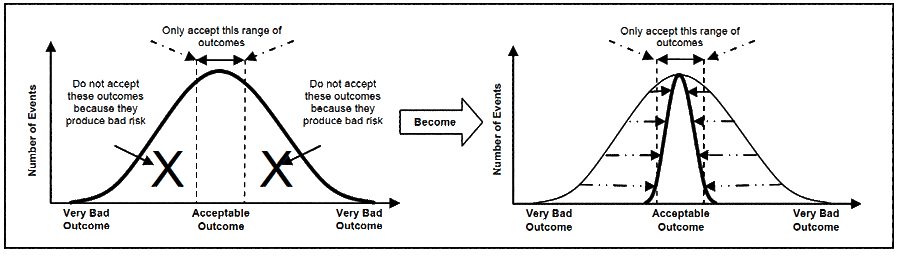
The left-hand diagram of Figure 4 is the normal distribution of random behaviour found in most business processes (though other shapes are encountered). It is a curve representing variability in outcome. The wide standard deviation allows many occurrences outside of requirements. An example where this curve applies would be the dimensions of manufactured parts where both undersize and oversize are bad outcomes. Another example is over torque or under torque on a bolt, where either could lead to failure. Such curves help us to understand the extent of the risk carried by our activities and processes.
The right-hand diagram still reflects the random nature of processes but controls are imposed to drive outcomes to within the acceptable range. You need to know which outcomes cause your problems and which cause your successes, and ensure you only do those occurrences that lead to high reliability and prevent those that cause increased chance of failure.
Behaviours of High Reliability Operations
The United States of America nuclear aircraft carrier fleet and nuclear submarine fleet are renowned world-wide as high reliability organisations (HRO). Starting with vision and leadership, it took a lot of consistent, persistent effort, and some tragic failures, to get there.
The nuclear submarine USS Thresher sank with 129 lives on 10 April, 1963. Though not recovered from its two and half kilometre deep resting place, the naval investigation review board used photographic and retrieved evidence, along with laboratory tests to identify failed brazed pipe joints as the most likely cause of the incident. The loss triggered a complete review of naval nuclear vessel design and operating procedures. Though the fleet’s equipment was built and maintained to high quality standards, and its personnel had specialist technical training, the quality control requirements became more demanding. Designs were simplified to remove complexity and behave in known ways. Quality control in manufacture was improved. Operating practices became more stringent to remove the chance of variation. Each crew member had to reach expert status in their discipline and on their equipment if they were to remain on-board ship.
The organisational structure on USA nuclear fleet vessels is unusual. The crew are the experts in running the ship and keeping it safe; the officers are there to support the crew in their efforts and address issues that reduce the crew’s effectiveness.1 It makes the operating crew more important to the ship’s survival than the officers; a true inverted organisation with managers at the bottom working for the producers at the top.
Central to the success of high reliability organisations is the realisation that everything can go wrong. The only sure protection is to know exactly what is happening with the equipment throughout the plant all the time. The equipment must be set-up perfectly at the start, and then monitored to ensure that it behaves exactly as it should when it is in use. What you don’t understand you don’t do yourself, instead you get help from those that do know until you are trained and expert enough to do the task. Human error is acknowledged and addressed with team work where people double-check each other constantly and documented checks, counter-checks and double-checks are a way of life.
High reliability organisations totally control every process and every step in those processes proactively. Nothing is unimportant because consequential knock-on means the smallest risk can be the start of the biggest catastrophe. It requires a dedication to diligence beyond what people in commercial industry are expected and paid to do. High reliability cannot be brought with money – it lives in the hearts and minds of people who want to be the best at what they do and are respected by their peers and managers for that expertise because it is so valuable to the success of the organisation.
The USA nuclear fleet’s equipment is designed for simplicity, high reliability and maintainability. The business systems in use demand proof of compliance to best practices. Its crews are educated to be a technical knowledge repository on their plant. Its people are trained to act skilfully in a highly reliable manner. The organisation is structured to put knowledgeable experts immediately at the situation of risk and danger and bring the power of teamwork into play. Those are key reasons why it is a HRO.
Limitations of Our Materials of Construction
We live in a probabilistic universe where its physics produces divergence and sudden change in the way matter behaves when it reaches critical points2. Unless the physics of a situation is controlled we get sudden changed behaviour in our materials of construction. The failure of equipment parts, and the resulting poor reliability and safety, is a direct result of the physical and chemical boundaries the material of construction is allowed to pass through. Poor reliability and poor safety is to be expected in organisations where its people do not know the limits of their machinery and do not understand what is happening to them every nanosecond.
People create high reliability when they know the physics of their equipment and expertly do their jobs to keep the equipment’s parts well within the capability of the materials of construction. The experience of HROs is that equipment failure starts with poor business system’s process control. The necessary systems and controls that produce high reliability are not present and followed. Equipment failures then result from out-of-control variation. The organisation’s quality management system fails first and then the equipment is failed by the system. To fix the management system failure it is necessary to go back and understand how business processes fail. By understanding how each process step can fail, you then can build-in the correct risk controls needed for high reliability from each step.
You cause your own equipment reliability through the quality management systems you use and enforce, along with the specialist technical knowledge your people know and you help them apply.
Raising the ‘R’
Improving reliability is not done accidently; there is no luck involved in having a world-class operation with outstanding equipment performance, low cost production, and a healthy and safe workplace. You start the journey to world-class performance by introducing its causes into your business processes. Then you teach your people how to do them exactly right. Your company will get high equipment reliability when its people do those things that raise the ‘R’ of every step in every business process across the life-cycle of its equipment. You must destroy the archenemy of reliability – the chance of unwanted variation – in every step and activity in your business.
High reliability means removing the risk of error in every process step and every workplace activity. You need to simplify methods. Use equipment so that it behaves in known ways. Train operators and maintainers to understand their processes and the equipment they use so that they are experts in them. Establish continual learning requirements covering the proper operation of the plant and equipment for everyone – from manager to cleaner. Develop fault-free, 3T proof-tested operating and maintenance procedures. Teach the procedures until your people are masters at doing them. Include continual checks and double-checks. Get people to check one another – apply the power of teaming-up.
Reliability Growth Cause Analysis (RGCA)
Improved reliability has a cause. Just like a failure has a cause, so too is there be a cause for improved reliability. You can wait for a failure and then learn from the experience and change your processes to prevent it. That is good, but it is not proactive behaviour. Such an approach buries you in fire-fighting and causes unnecessary loss and waste. Rapid reliability improvement applies proactive methodologies to identify potential problems and stop them starting. This is what is done in HROs.
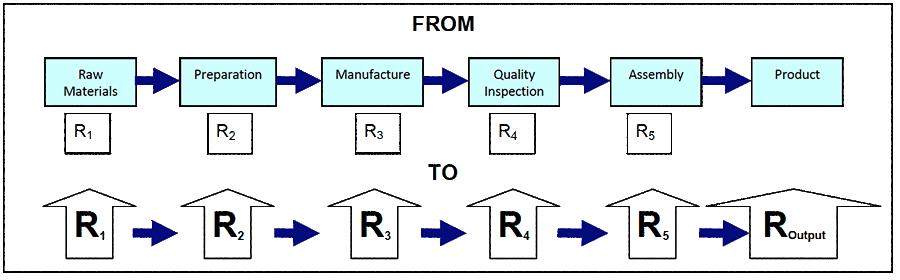
Figure 5 highlights what must be done. You intentionally raise the ‘R’ of every process step, activity and part. You move reliability from its current boxed-in performance and force it higher. One by one you find the risks contained in each step, activity and part and act to reduce their chance of happening by orders of magnitude. Once chance of failure is reduced in each step, the likelihood of getting the required process outcome naturally rises.
The process maps of your business processes, the workflow diagrams of your operating procedures and the bills of materials for your equipment are the foundation documents for improving equipment reliability. They are used respectively to control variation in the business processes, to control human error and to address limitations of the materials of construction.
To get high reliability, the experience of the HROs tells us, we must put into the business those processes and activities that cause high reliability. If you want to be proactive about reliability you need to find every possible failure and problem that can arise throughout the business in order to decide how bad it is, and whether it needs to be intentionally prevented. First draw a process flow diagram for each process and for each task in the process, and for each activity in a task. Figure 6 shows how to trace a manufacturing process step down to its very fundamental tasks and actions. Now you have the detail to see where your problems start.
Reliability Growth Cause Analysis is based on using cross-functional expert teams brainstorming to find the causes of reliability in business processes or equipment parts. You ask what you can do to intentionally to remove the risk in a situation, or to an equipment part, that can cause situational failure, which by preventing thereby increases situational reliability. Box by box, or part number by part number when equipment bills of materials are used, you assume a failure and identify the various failure modes that can cause the failure. With the team you complete the details listed in Table 1 for each failure mode. Together the team then identifies the risk reduction strategies (design, operational, maintenance and skills) to use to deliver reliability growth.
The spreadsheet highlights the total business-wide costs, the DAFT Costs (Defect And Failure True Costs), of failure in a process step, task activity or equipment part. This provides a financial justification to later implement worthwhile changes. The analysis asks people to list the causes of both stress/overload and fatigue/degradation in each step, activity or part. It is not failure that is identified; rather it is the situations that cause the failure. Risk is lowered as far as practicable.
The proposed changes are compared before-and-after on a risk matrix to ensure they will lead to noticeable risk reduction. A plan is developed to introduce them, including the necessary training people need to become expert at performing those tasks that cause reliability.

As you perform Reliability Growth Cause Analysis you complete the details of Table 1 for every process step using a spreadsheet such as that shown in Figure 7.
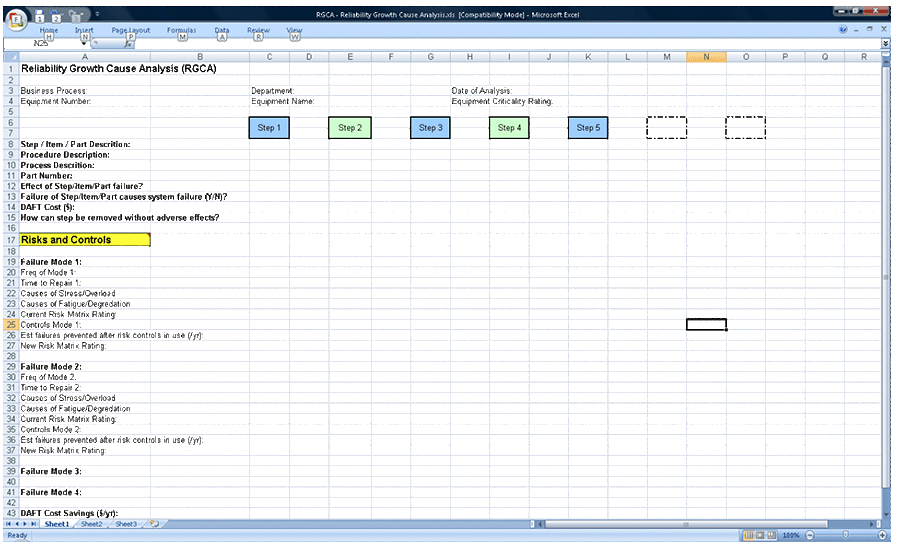
With knowledge of what makes a step, activity or part fail, the team selects the skills, practices and procedures that prevent stress and fatigue in that step, activity or part. These are the actions that need to be taken into the organisation’s methodologies and practices and trained into its people; just like they do in a HRO.
At the completion of the RGCA process you will have a list of the necessary activities and skills that will deliver high process step certainty and equipment part reliability. Those activities then need to be put into place in your business processes and the right skills developed to expert level in the people that need to do them.
Finding the cause of reliability growth is demanding on resources. It becomes even more so during implementation of needed changes. But without making those changes reliability can never get better. If high reliability were easy, every company would already have it. But high reliability is exceptional because it has been so hard to do well. Few organisations dedicate themselves to becoming so good. Without the tools to find exactly what they need to focus on, without the evidence that high reliability is worthwhile and without an achievable plan to deliver it, organisations will waste away.
Realise that once an RGCA is performed, and the right reliability growth actions, knowledge and practices are identified, they apply to every similar situation. Do an RGCA on one bearing and you have done it for all bearings. An RGCA done on a production task applies to every such task done in the operation. Take the learning from the one analysis and apply it to every similar situation across your business. Rapid reliability growth can happen in only a matter of months when best practices are cascaded across a business.
When reliability improvement efforts identified in a RGCA are implemented and practiced, the chance of failure-causing incidents drop. You will evidence a clear reduction in the number of equipment failures because the right actions to produce reliability are done at every stage in a business process, workplace task and a part’s life. Your operating profits will reach sustainable higher levels. Your safety and environmental performance will become the envy of your industry.
Welcome to world-class!
Conclusion
Be realistic – there are no short-cuts to outstanding reliability. Equipment reliability results from precise control of the causes of variation at every point in the life-cycle. It takes vision, hard work, persistence and courage against complacency to make reliability growth happen. But it can be done quickly; measured in months and not in years, when the right change management processes and methods are used, compelled by the desire and need.
World-class reliability cannot be brought. It requires a corporate vision that drives improvement of business management systems and processes; that creates competency and supports situational leadership; that drives engineering knowledge growth and expert skills development in the workforce, correctly applied to improve equipment condition and remove operating risk; and that sustains it all by changing personal values and attitudes to those which cause and sustain outstanding reliability.
Mike Sondalin
Lifetime Reliability Solutions

Leave a Reply