
The rest of us are missing the boat!
RCM has two potential uses – to set you up for success or to regain success from the jaws of failure.
Regardless of when you use it though, RCM alone isn’t enough to get all the benefits. Applying it after the systems are in service, to recover shortfalls in performance, and then failing to follow up on RCM’s results only delivers part of the benefit. That’s where the aircraft and nuclear industries and the military have it right – they take those extra needed steps. The rest of us don’t!
What they do differently
RCM outputs can be leveraged to provide additional logistical benefits that go beyond the immediate goal of achieving high levels of reliable performance and risk reduction. Improved performance reduces demand for corrective repair work, RCM sets the schedule for proactive work and knowing both there is an opportunity to define and streamline support requirements enabling optimum investment in support to ensure desired system performance – risk reduction and profitability.
Where RCM has been applied at the development and design stages there is an opportunity to define and optimize the entire support infrastructure for the new system.
Where RCM is applied to systems already in service, there is an opportunity to fine tune whatever support is already in place.
In both cases, maximum benefit arises from the leverage we can gain from the knowledge that RCM provides about our systems, how they fail and how to manage their failures. The benefit of that leverage depends on actions taken after the RCM analysis is completed as shown in the diagram below. There is an entire process that most of us overlook – and we pay dearly for it.
RCM has three primary outputs – tasks (with complete descriptions), task frequencies (based on solid technical risk and cost based criteria) and definition of who should do the tasks. There are other outputs as well: decisions in some cases to run an asset to failure, identification of the need for design, procedure, skill, and knowledge or process changes to eliminate failure causes, make failures more evident and reduce risks associated with their occurrence. These are all failure management strategies.
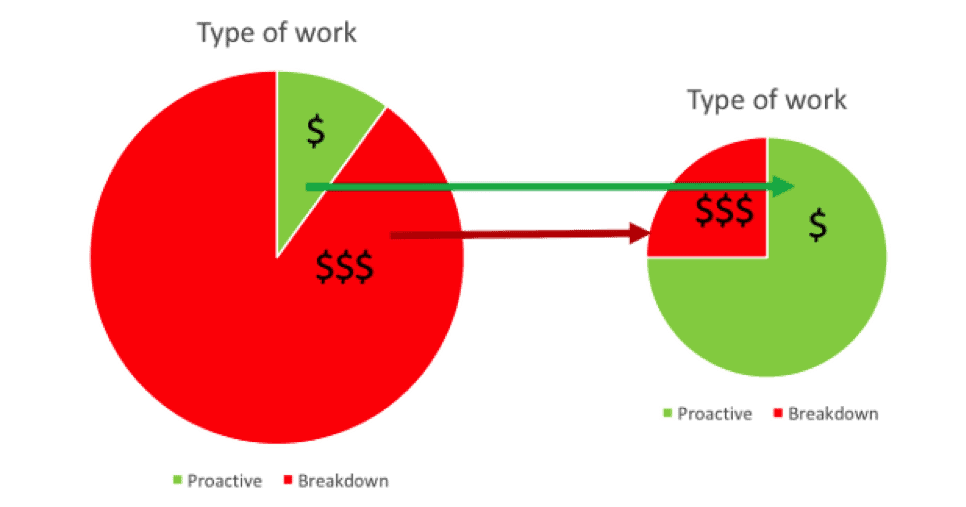
Those output failure management strategies are thoroughly justified on the basis of technical feasibility, risk reduction and / or costs. Yet clearly defining what to do isn’t enough if we don’t do what is decided and leverage the knowledge of those outputs fully. We know that despite its success in the military, airline and nuclear industries, RCM programs elsewhere often fail to achieve their desired goals and some don’t get beyond the technical analysis phase. All are using the same basic methodology – RCM, but not all are getting the results.
RCM is a bit like golf and baseball where we see the best shots / hits only when we see perfectly executed follow-up. In RCM, the follow-up action isn’t just an artful swing – it’s a set of actions. The obvious and immediate actions are defined, failure mode by failure mode and they include steps to:
- Put new or changed procedures in place,
- Update CMMS / EAM with new and revised maintenance tasks and frequencies, and
- Initiate design changes.
Those are the immediate requirements and sadly they don’t always get implemented, rendering the analysis all but useless. That happens if RCM is treated like a project – it will have a beginning and an end. Often its output is treated as a deliverable and “others” are responsible for those follow up actions. In some cases those who need to take action are blissfully unaware of the outputs and their role in following up. In those cases where that work is done however, there is a lot more that can be done to ensure full benefit from the analysis effort.
In the diagram below, the definition of tasks, engineering and other changes are immediate outputs from RCM appearing on the left hand side. The project deliverable often comprises those first two blocks – carry out the analysis and deliver decisions. As the diagram depicts though, there is a full life cycle support requirements definition process and then staging that follows. The rest of the diagram shows additional actions that can be taken to set yourself up for success.
There is an old saying that “failing to plan, is planning to fail”. This diagram depicts a basic process for “planning to succeed”.
Defining Life Cycle Support Requirements
Wherever a failure can occur or is allowed to occur (run-to-failure decisions) there will be a requirement for a maintenance repair job plan. Even where we take proactive steps (condition based, detective and preventive maintenance) we have a requirement for a maintenance job plan. Those plans define what is needed for execution of the job (i.e.: parts, tools, test equipment, lifting apparatus, transport, shop capabilities, skill sets (trades), documentation and drawings, and time to do the work).
Comparing existing maintainer or technician skill sets with those required to carry out the various defined jobs can reveal the need for additional skills, knowledge or abilities – i.e.: maintainer training. Similarly, for defined operator tasks or checklists, we have a need to make sure the operators have the capabilities – i.e.: operator training.
Taking those plan outputs a bit further and comparing what is needed to provide them with what you already have in place, you arrive at a full definition of what you need to add to provide that support – i.e.: the support infrastructure. That consists of training facilities or training providers, store rooms and their optimal locations, tooling and tool cribs, support equipment (e.g.: carnage, transport, shop equipment and tooling) and documentation to support it.
Spare parts are defined when we prepare job plans. For spare parts we know there will be a recurring demand and we also know (from the RCM analysis) the demand rates. We can forecast immediate and future spares requirements, set min/max levels, define parts’ specifications, identify suppliers and lead times. For repairable items we can carry out repair vs. replace analyses to determine if repair is economic. By estimating repairable item attrition rates (i.e.: how many do not make it back from repair) we can forecast how many spares to carry for those repairable items. In taking these actions we enable our supply chain to position itself well to support the reliability program. We inform it of future demands with plenty of lead time and enable it to meet those demands. Our supply chain becomes as proactive as our reliability program.
This also has the potential to remove one of the biggest irritants to maintainers and stores people in operational environments – the mutual antagonism over a lack of the right parts and sufficient warning to procure them. Instead of being antagonists, your future maintainers and supply chain become partners.
Once that is all in place, the operation (new or existing) is well positioned to achieve its designed-in reliability characteristics that are inherent in any physical plant or asset. That is a huge improvement for many operations where maintenance, supply chain and operations are often working at cross purposes due to a lack of understanding and full definition of what they must do to ensure successful operation.


Leave a Reply