
There is no question that standardizing processes, techniques and best practices has contributed greatly to technological evolution. Just writing down or passing on what has worked well in the past helps anyone’s learning process. But there are many problems associated with this approach when blind obedience kills critical thinking.
This is the seventh article in a series that looks at how reliability, risk and safety interplay within emerging technologies. The previous articles examined the over-reliance on ‘compliance-based’ frameworks, containing checklists of what design teams must do instead of what the product must do. These articles also talked about how instead we need to toward ‘performance-based mission assurance’ frameworks, with the mission truly revolving around what the product does – not what you think the design team ought to be doing. And the previous article talked about evolutionary production and how this needs to be applied to emerging technologies.
The trigger for this series was my recent involvement in helping some small satellite industry stakeholders. Small satellites are an emerging and perhaps disruptive technology in the satellite industry. They are different to their older, larger predecessors. And there are many issues arising from old practices dying hard.
This article talks more specifically about what we actually did to help out a small satellite manufacturer, and what framework we developed to improve satellite reliability. At the heart of this new approach is a focus on ‘assuring culture’ as opposed to ‘assuring compliance.’ This sees assurance move away from a checklist of activities and toward a robust design and decision-making processes that are well researched and continually improve. Instead of designers being motivated to align with standards or guidelines, designers are motivated by providing value to customers. This may mean that reliability as a metric is not (at least philosophically) ruthlessly maximized – this is a design constraint that costs money. Instead, understanding reliability, how much it costs to improve it, and what alternatives exist (such as the launch of multiple satellites) to create value for the customer needs to be rewarded.
And while we are talking about small satellites, the aim of this series is to broadly deal with all emerging technologies, as the problems we see with one emerging technology tend to repeat for another. The key thread is human nature – which at its best is inspiring and at its worst is destructive.
Let’s start at the finish and work backwards
There are four key things that future satellite mission assurance frameworks need to do or provide:
- Implement proactive assurance frameworks – not responsive, slow, overly consensus driven standardization that competes with critical thinking.
- Race to find failure causes during the design, manufacture and testing processes as opposed to finding failures during operation.
- Automate responses to problems in a way that the organization is structured to implement ‘good ideas’ from its people and not rely on ‘local heroes’ to make things better.
- Promote an assurance of culture and not a culture of assurance.
Failure is a random process. This could be news to you. We can never measure the parameters that govern failure processes. This makes reliability engineering hard. Increasingly hard for ultra-reliable devices where we don’t have hundreds of prototypes to test, or even if we do we don’t have enough time to see them fail in our laboratory. And unfortunately, randomness gives us false senses of security when something ‘works.’
The difficulty in measuring failure process parameters means some of us try and replace ‘mission performance’ with other things. Like passing qualification tests, being certified as compliant and so on. And as these get more and more difficult to critically link to performance, consensus standards emerge. Standards that are backward looking and (by definition) not relevant for a new, emerging technology.
There is ample scope for designers and managers alike use the random nature of failure to kid themselves that what they are doing is good. That until told (or demonstrated) otherwise, the thing must be considered reliable or immune to criticism.
Winning, Reliability and Safety
Human beings want absolutes and to focus on the positive. We are not emotionally wired to deal with ‘trends’ or ‘probabilities’ – particularly if these focus on the negative.
Designing a system or coding software is based on the physics and logic of success. Conversely, reliability and safety are based on the physics and logic of failure. The latter is inherently negative, and difficult for human beings to psychologically embrace. No system or organization ‘wins’ in terms of failure: they either ‘lose’ or ‘don’t lose.’
Without ‘winning,’ it is very difficult for organizations to focus on reliability and safety, particularly when they get an instant gratification from focusing on the physics and logic of success. And because they are made up of human beings, organizations start to crave instant gratification. That is, they move away from reliability and focus on other things like functionality, time (schedule) and cost (budget).
And this need to focus on what ‘we think works’ permeates virtually every human endeavor where we have to wait and see what actually works (or doesn’t).
Consider the history of the 100-meter sprint. Sprinters were prototypically short and muscular. This is what sprinters ‘had’ to be. Then 6 foot 5 inch Usain Bolt came along. If we used compliance-based frameworks to identify potential sprinters, we would never have Usain Bolt. And more importantly, human beings would not know how fast we could run. They would also never strive to be the fastest ever. We would only ever see the fastest ‘short and muscular humans’ and hope that these are our fastest people.
So how do we approach safety and reliability the same way as Usain Bolt does? The first thing we need to do is to stop doing the things the way they have largely been done – assurance guides and standards need to focus on rewarding organizations who ‘train to win,’ – not organizations who are only interested in ‘not losing,’ ‘being seen to want to win’ or ‘cheating.’
Small Satellites and ‘Designing to Win’
Other industries have framed the challenges of creating a genuinely safe and reliable system as moving ‘beyond compliance.’ The response to many failures, catastrophes and disasters has been to impose more standards and regulations. But we keep seeing failures, catastrophes and disasters on the news virtually every day. Why? Because many organizations don’t want to adhere with the intent of compliance. This costs them money, and sometimes customers don’t reward them for their thing not failing in the future.
Small satellites are fundamentally different to large, single payload satellites that became the norm by the early 2000s. Small satellites ushered a pioneering spirit that perhaps was only previously evident at the start of the ‘space age.’ It is no coincidence that small satellites were often developed by graduate students and others unshackled with traditional satellite design thinking. A new and inexpensive way to gather data from above the Earth’s become a reality despite a complete lack of confidence by experienced satellite designers of the day.
But while the decades of preconceived ideas didn’t limit design (the ‘physics and logic of success’), they certainly shaped mission assurance (reliability – the ‘physics and logic of failure’). Standards, regulations and mission assurance guides (which struggle to keep up with even clearly defined technologies) are not remotely suited to transformative systems like small satellites. This mismatch risks creating another sort of an organization: one that is ‘constrained from training to win.’
Risk management of emerging technologies
There is little in the way of positive exemplars in how we manage the risk of emerging technologies. This is because once a market gets used to the risk of an extant or mature technology, it is difficult to then accept more perceived risk. And most discussions to date focus on systems with widespread safety implications.
In short, no regulatory or assurance framework has ever been able to demonstrate a comprehensive and useful approach to the design of safe and reliable emerging technologies. It is difficult to overcome widespread opposition or concern once manifested. This is particularly evident for things like genetically modified food and nanotechnology. From nuclear power to biotechnology, once suspicion is amplified by non-scientific emotions and concerns, we produce a ‘crisis of trust.’
It is this mechanism that means we don’t have autonomous vehicles safely operating on roads today. We know that in most countries, around 95 per cent of road deaths are caused by human error. Autonomous vehicles are the only vehicles that are tackling this main source of risk. They are also the only vehicles that ‘we’ are too scared to allow on the roads. And before anyone suggests they are not ready, just visit the websites like the California DMV homepage which lists all the incidents experienced by the test autonomous vehicles being driven on public roads. Of the millions of miles driven, the overwhelming majority of vehicle incidents are caused by the other driver. Why are we still debating this?
You can’t regulate or assure critical reasoning
There are two approaches to regulation: anticipatory and reactionary. Most regulation and assurance frameworks we see today is reactionary (and has often served us well). Most attempts at anticipatory regulation have been spectacular failures.
The late 1800s saw the emergence of the automobile. Lawmakers in the United States and United Kingdom identified the potential for safety concerns. This saw the advent of the ‘Red Flag Traffic Acts.’ These acts required a man to walk 60 yards in front of the automobile to warn of the vehicle’s approach.
The lawmakers did not understand the technology. They did not understand that the main safety risk was to those on or inside the vehicle.
The single most effective device that has improved automobile safety was the seat belt. Seat belts were invented in the mid-1800s. Seat belts were incorporated in some automobiles form the early 1900s, but were not mandated in the United States until 1967. Over a hundred years went by before the most important reactionary regulation for automobile safety came into being.
Small satellites do not have that sort of time.
Are there any good examples?
Yes, and we will talk about one now.
Netflix contains perhaps the most reliable cloud computing infrastructure in the world, noting the volume of data it is responsible for transmitting. We say ‘perhaps’ because no one (including Netflix) knows how reliable its systems are in a quantifiable way.
So how does Netflix assure a reliable system? They don’t focus on the ‘how their system is designed,’ the focus on ‘how their system works.’
Netflix created a suite of programs that they refer to as the ‘Simian Army.’ It is so called because each program is referred to as either a monkey or an ape. ‘Chaos Monkey’ was first created to randomly disable virtual instances in a controlled manner. Software engineers would observe how the system would fail, improve the code so that it could handle such an issue in the future, and then repeat. ‘Chaos Kong’ was developed to disable entire geographic areas to see how Netflix’s system would react. These programs are run daily without the customers being aware of it. The result is a highly reliable system, even if the reliability cannot be quantified.

Netflix’s representation of its ‘Simian Army’
The Simian Army would most likely not satisfy any compliance based or reactionary approach to regulation. A reactionary approach requires an observation how something can fail or create risk. Once we are aware of this, we can then mandate something be done about it – like install a seatbelt.
The Simian Army is uncovering these risk sources by simulating them, and then having mitigation activities rectify any observed issues. So, the Simian Army is the regulatory framework. But it itself cannot be regulated – at least not yet.
Small satellites are full of failure causes we don’t fully understand. The compliance-based frameworks have not ‘reacted’ to the way small satellites fail. And the typical reactionary cycles of these compliance-based frameworks do not align with the rapid development timelines of small satellites. So current compliance-based frameworks make small satellites commercially untenable should they be enforced.
Article 3 of this series talks about how organizations such as Hewlett Packard and Du Pont essentially threw compliance-based frameworks away. By focusing on performance, they save billions of dollars. So we know focusing on performance works, and focusing on compliance doesn’t.
Less Process Monkeys and More Simian Army
But now we have the problem of trying to create an assurance framework based on culture that can be assessed by respective customers in a formal way. Netflix doesn’t have this problem – a customer’s decision to move to another service provider should they experience problems with reliability is informal. When small satellite manufacturers deal with governmental and military customers, informality is not an option.
So what did we do for small satellites? We introduced some key principles.
The Gold Suite
Small satellites need to be based on an evolutionary design process to the fullest extent possible. This involves the development of something like the ‘gold suite.’
The term ‘gold’ often refers to a datum or fixed ‘thing.’ This emanates from the way that (precious metal) gold was used as a monetary standard. In engineering and calibration, the ‘gold’ thing is often a system or device whose characteristics are precisely known, forming the basis of all future measurement and development.
A small satellite gold suite comprises three things:
- the ‘gold satellites,’
- the ‘gold backbones’ or perhaps ‘gold BUSes,’ and
- the ‘gold toolbox.’

The Gold Suite
The gold satellites are fully designed satellites for specific missions. Customers can select specific gold satellites, and (if needed) request modifications that represent a deviation from this known but robust design baseline.
The gold backbones are a set of satellites that contain essential modules and components only. They are specified by payload requirements – not missions. Customers (with payloads) can then select the gold backbone that is most appropriate. Again, this maximizes the use of a known and robust design baseline.
The gold toolbox contains a set of modules and components that can be incorporated into gold satellites and backbones at the customer’s request. This maximizes design flexibility while still incorporating evolutionary design.
This may feel like a formalization of already good design practices – and it certainly is. But it is uniquely tailored to small satellite design. And by saying this is how we make satellites, every designer and manufacturer knows why they are doing the things they do. One of the appeals of small satellites is that it is feasible for them to be designed and manufactured in relatively short timeframes. The gold suite not only needs to accommodate this, but it supports it.
The gold design process is illustrated below. Each customer engagement represents a chance for the gold suite to be updated with lessons learned and incorporated into the baseline designs. It may also become internally apparent that these baseline designs need to be updated. For example, a new technology or technological application may arise that necessitates change.
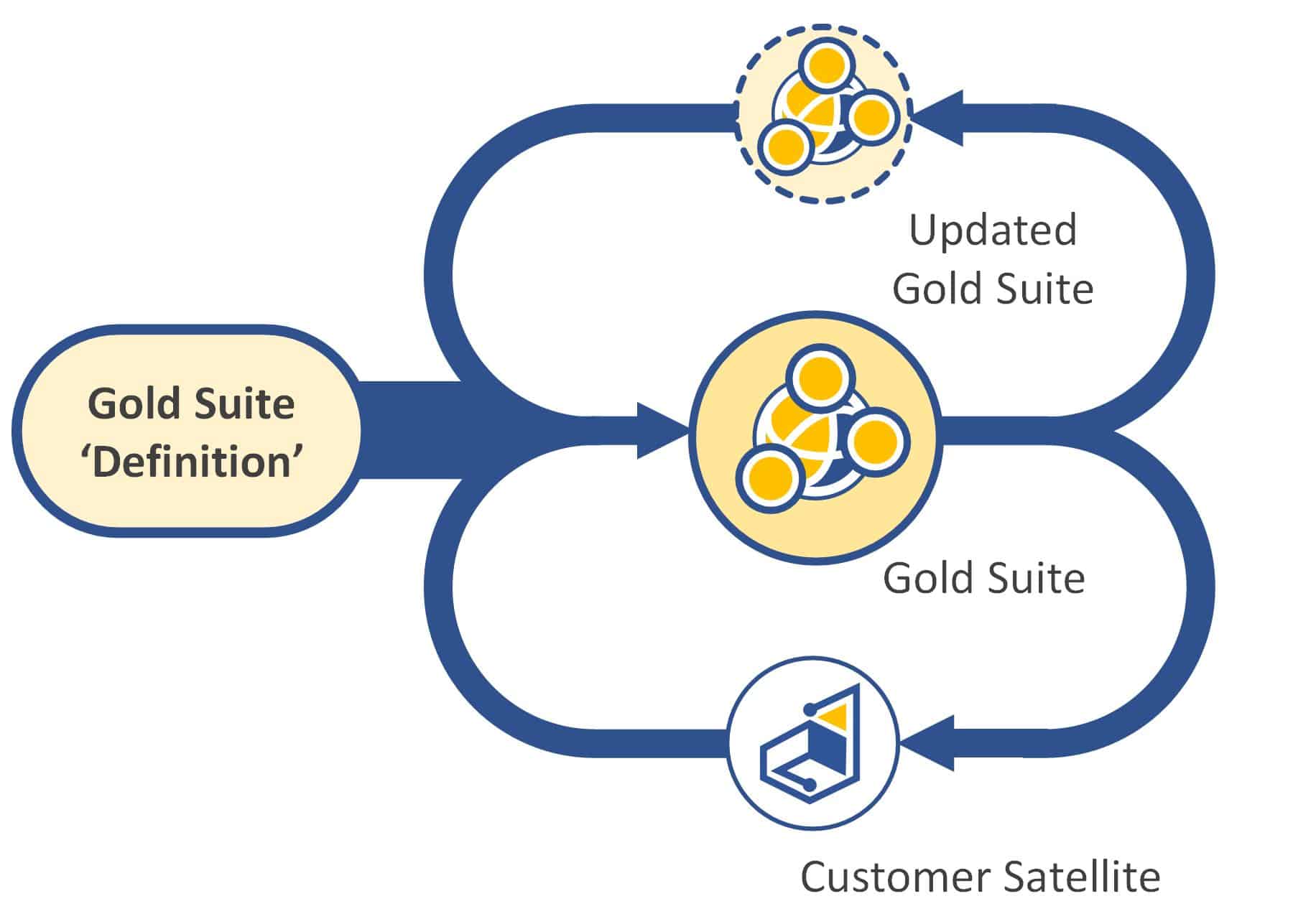
Proposed gold design process
A New Quality Management System (QMS)
Understanding what we want to do is one thing. Understanding how (we think) we want to do it is another. Formalized business processes are the first step – without processes there is nothing to improve.
A QMS is a set of policies, processes and procedures required for planning and execution in the core business area of an organization. QMS tend to focus on traditional perceptions of quality, particularly those that revolve around defects. Other QMS are simply focused on keeping documents up to date. These traditional QMS do not (for example) look at quality as the ability to handle defects.
It is unlikely that Netflix’s Simian Army would satisfy an external audit for ‘compliance’ with QMS requirements, and this is a problem. One of many examples is that QMS are seen to require measurement of performance. Netflix’s Simian Army can’t do this.
The QMS we came up with for our small satellite manufacturer is illustrated below. It consists of six arms that are not traditional. The intent is to implement what the Simian Army does: encourage all practices that identify design characteristics that could result in failure before that failure occurs. A basic review of quality standards such as ISO 9000 reveal a bias toward process (and compliance) – not culture.
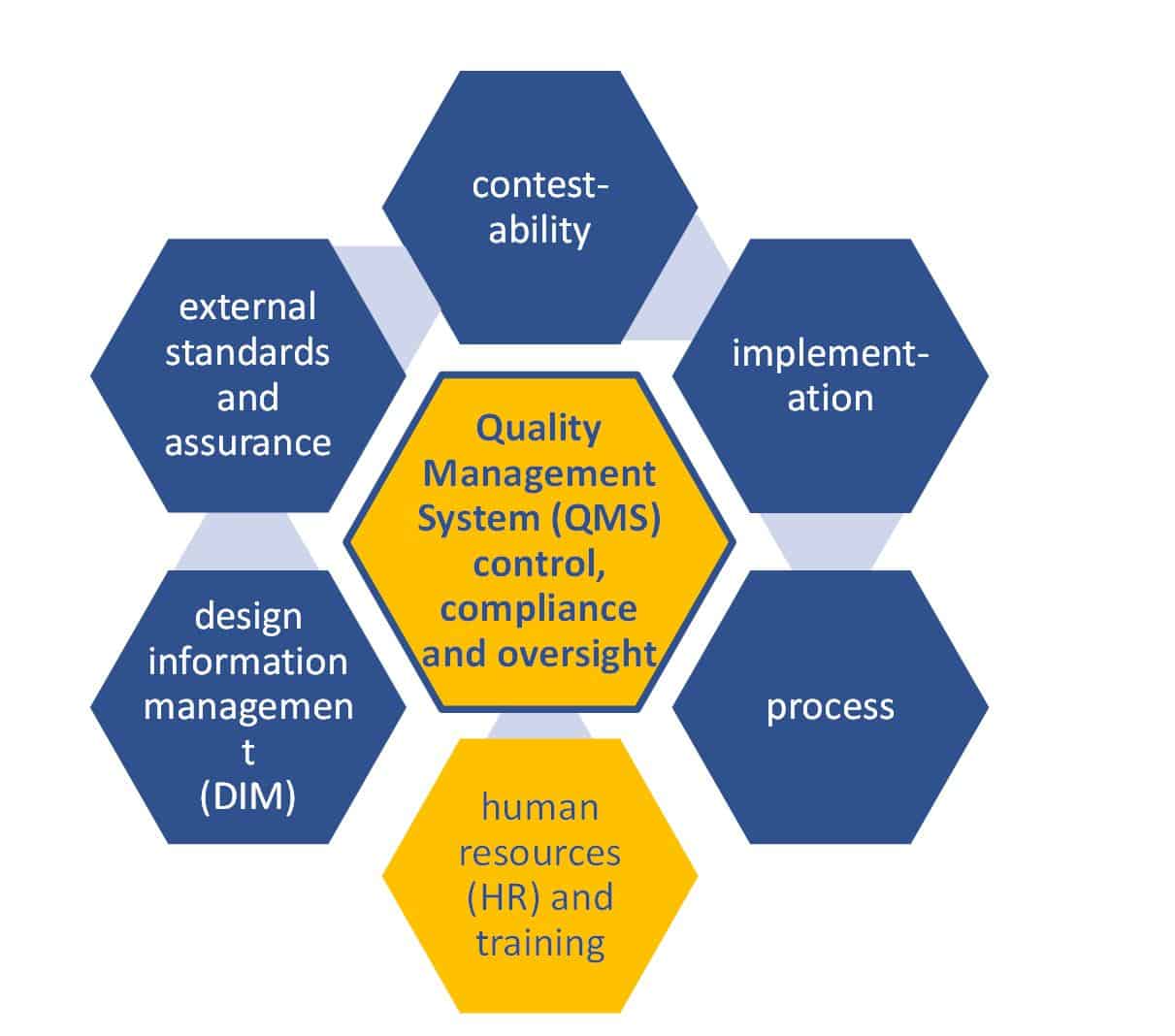
Proposed Quality Management System (QMS)
The key objective of the QMS is to learn – not formalize. While formalization is a key and enabling step, it is not the outcome. Many compliance centric regulatory frameworks forget this: formalizing enabling steps does not formalize the desired outcome.
The QMS Control, Compliance and Overview Arm’s mission is to implement the QMS in an efficient and effective way. These are the people that make sure all these steps interact and support each other in the right way.
The DIM Arm’s mission is to motivate engineers, designers and developers to assist improving corporate knowledge that informs design decision actions through easy organization-wide access to this evolutionary body of corporate knowledge. In short: corporate knowledge is sought, interrogated, maintained and made available in a user-friendly way so engineers don’t have to look for it.
The External Standards and Assurance Arm’s mission is to deduce and explain a Standard of Standards document that links external ideas of industry best practice to application in small satellite design based on relevance and benefit. This would see all small satellites designed in a way that complies with the Standard of Standards, which is discussed next. For example, if there is an outdated standard that deals with a particular failure mechanism associated with a polymer glue. The standard is outdated because that polymer glue is no longer used and doesn’t have that failure mechanism anymore. The standard required the old polymer glue to have its temperature strictly controlled. The Standard of Standards would list this outdated element of a standard and explain why it is being complied with even though the manufacturing process does not control the temperature of the polymer glue anymore (it doesn’t need to). So the Standard of Standards in this instance replaced the outdated standard to control the temperature of a polymer glue with a new practice of using better polymer glue. All the while ensuring the rationale can be traced back to the original to give the customer confidence that the intent is being complied with.
While onerous, this is the ultimate way to encourage critical thinking to replace compliance in a way that should guarantee a constant march toward best practice.
Put simply, the Standard of Standards is based on knowing the intent of the original standard and determining (through critical thinking) if this aligns with the physical outcomes of imposing or adhering to that standard. It is that simple.
The Contestability Arm’s mission is to ensure that engineers and designers are resourced, enabled and motivated to identify all possible failure mechanisms, defects and software errors as early in the design process as possible. The contestability arm is led by the senior satellite engineer who can challenge conventional thinking in a proactive way. This is the arm which drives engineers in a race to find failure and not a race to pass tests.
The Implementation Arm’s mission is to execute activities that benefit the entire organization through economies of effort and commonality, represent specialist projects or actions outside the typical scope of designers, engineers and developers, and allow employees to focus on key responsibilities. If there is a single practice identified in one branch that could benefit all others, then the implementation arm identifies it and teaches everyone else about it.
The Process Arm’s mission is to establish, maintain and continually optimize business processes, their guidance documents and user interfaces. The Process Arm includes what many organizations refer to as an ‘operations manager’ that oversees processes and allocation of activity responsibilities.
The HR Arm’s mission is to attract, retain and develop personnel.
The interaction between the proposed gold design process and QMS is illustrated below.
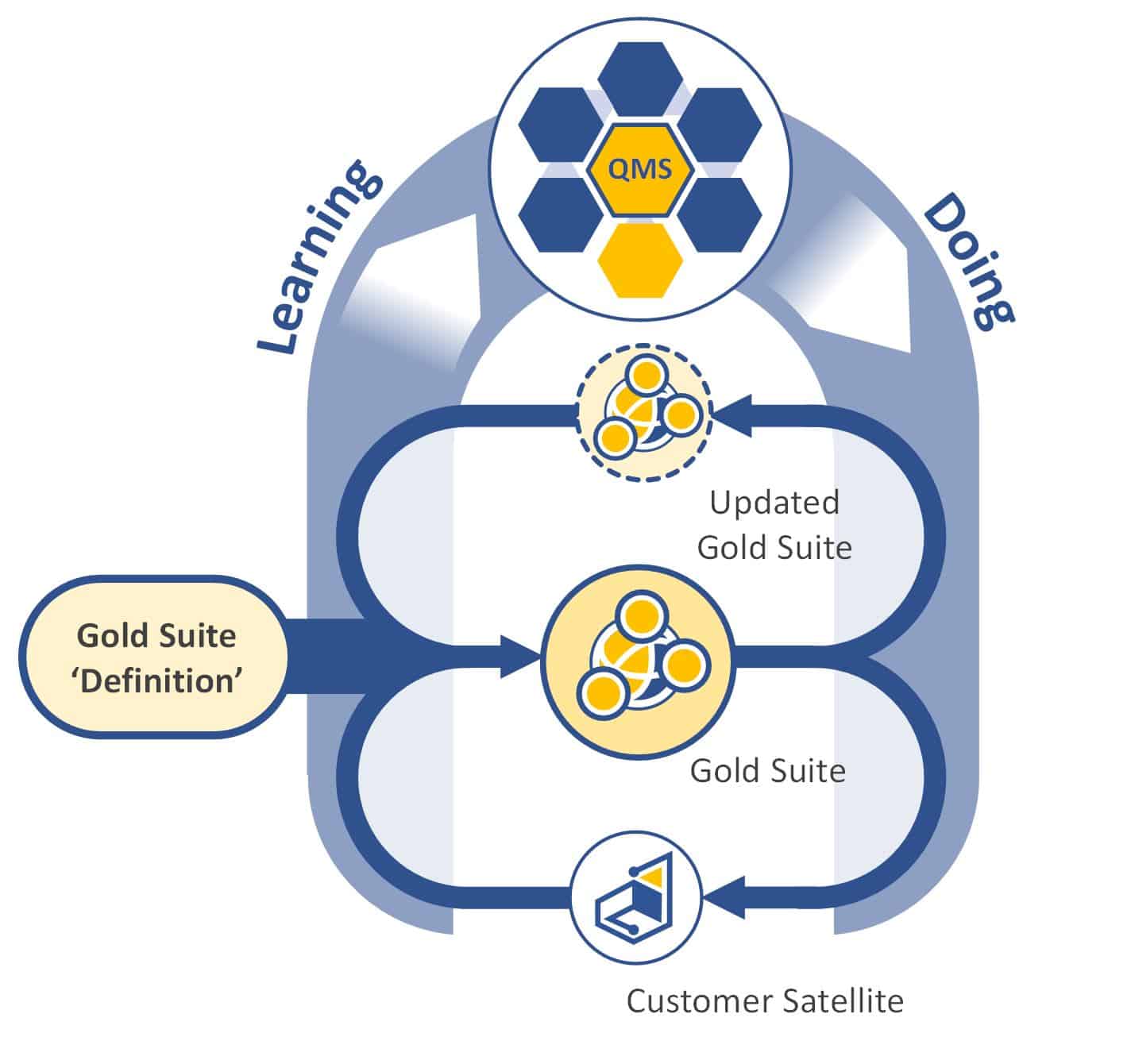
Proposed gold design process and QMS
What happened (… or is happening)?
Nothing yet. This is brand new. And it will likely need to evolve as the realities of deployment come into play. The first adopter of this approach is small satellite manufacturer Tyvak Nanosatellites Systems Inc. And no doubt they will have their own story to tell one day as we are talking about cultural change.
But this is almost besides the point. Because what is changing is that we are now empowering engineers to learn and do. Not learn and complain about how they are being forced to do things that don’t work. And part of that change is when we identify scope for improvement – the organization makes it happen.
Entrepreneurs and pioneers of new technological paradigms may believe that their challenges are the first time they have been experience by anyone. While certain aspects of challenges are always dependent on context, it is remarkable how many are principally identical those experienced by yesterday’s entrepreneurs. New technologies have already challenged our thinking in terms of safety and reliability, and we would be foolish to not learn lessons.
The quote culture eats strategy for breakfast is attributed to the father of modern management: Peter Drucker. He is correct. From Fukushima to the space shuttle program, culture beat all attempts to improve reliability and quality. Hewlett-Packard and DuPont thought they were doing all they could to maximize quality and reliability – but they were doing no such thing. And companies like Netflix are doing things that eschew categorization with traditional quality frameworks, and yet they have industry leading performance.
So why do we observe a tendency for compliance? Because it is easy (and lazy). A compliance framework is auditable. A culture is not. Customers sometimes value the ability to defend their decision more than making the right one. Therefore, we have regulatory frameworks that cannot prevent the next Deepwater Horizon and multiple organizations searching for something that is beyond compliance.
Can the gold design process and the learning QMS be independently audited or assessed as ‘compliant’ with best practices? Can the culture it reflects ever ultimately be assured? As mentioned, several agencies and organizations are trying to answer these questions while hoping that the answers turn out to be ‘yes.’ If we can say ‘yes,’ then the four things we mentioned at the start of this article. They are worth repeating here – with slightly different words:
- Proactive Assurance Frameworks – not Responsive. Truly ‘reliable’ developed their own approaches to reliability and quality based on critical reasoning. These approaches are now de facto standards.
- Racing to Find Failure Causes but not Failures. A failure can only occur once a satellite is on a mission. It cannot ‘fail’ in a laboratory. This may appear semantic (of course you can stress something in a test environment to the extent that it will break), but failure is only failure if the customer does not get what they ask for. So, testing a satellite until failure helps us identify a failure cause.
- Assurance Frameworks that automate responses to problems – not implement suggested responses from others. Standards are the responses or mitigating activities that a body of experts have decreed is necessary to prevent something that happened long ago happen again. Small satellites are routinely designed by customers who ask that they adhere with standards that are not relevant. With the demands of ever changing technologies, we cannot rely on standards to be developed to answer all our small satellite design problems.

What reliability and availability assurance ‘truly’ looks like
This is fundamentally different from the traditional compliance approach, where the solutions of others (that have gone through perhaps long, arduous and inexact ‘standards’ reviews) are imposed on the design process as illustrated below.
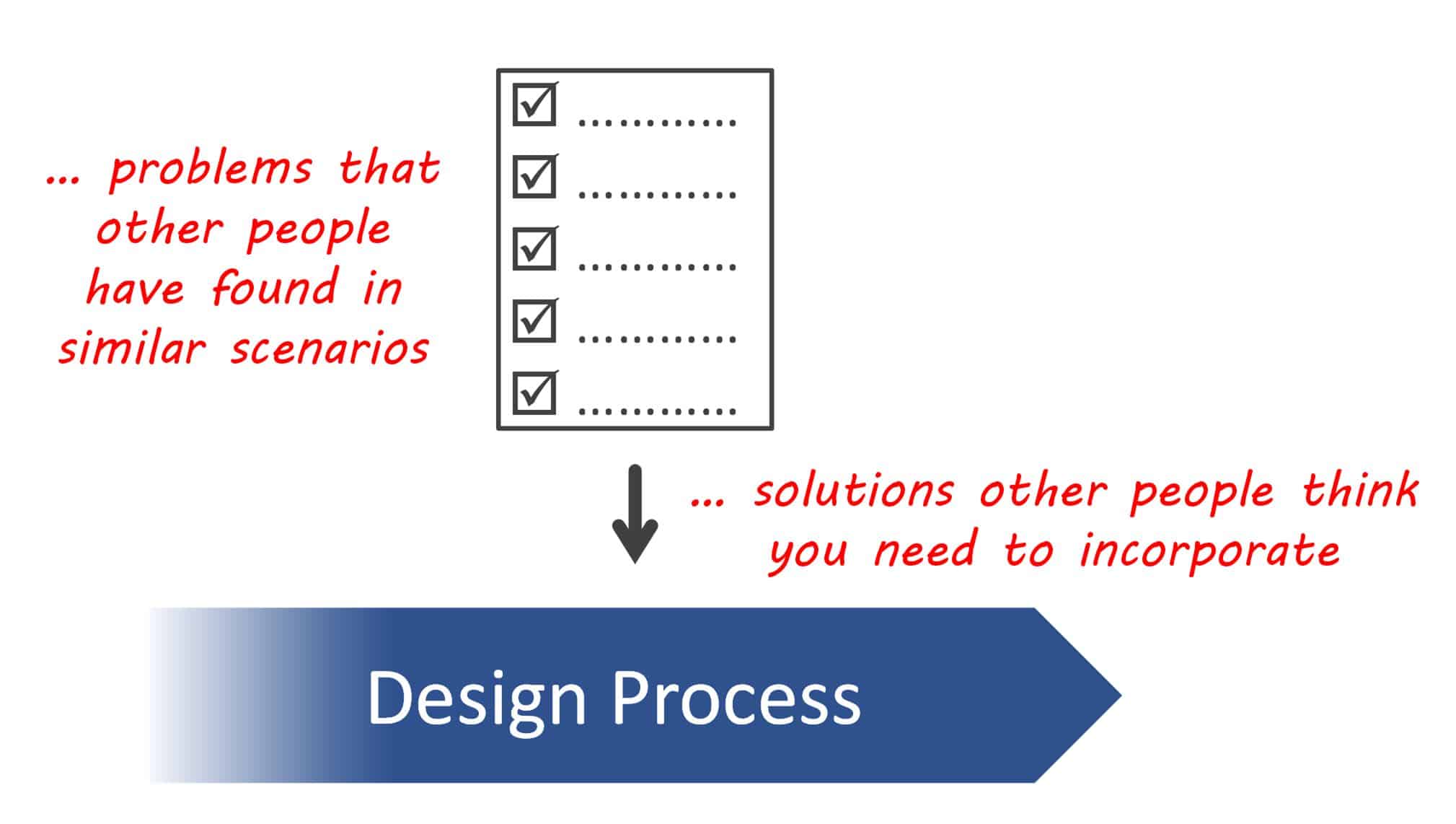
What compliance-based reliability and availability assurance actually looks like (and really shouldn’t)
- Create an assurance of culture and not a culture of assurance. This is the key challenge. How can a third party walk into small satellite manufacturer and conclude that they have a culture that results in reliability and quality? Anticipatory regulatory frameworks have spectacularly failed, and reactive regulatory frameworks are beneficial for relatively stagnant technologies. But it can be done. In the same way John Hopkins Applied Physics Lab stopped asking their staff to identify compliance issues and started demanding they show how they have improved their systems, we (everyone) can do the same. It just takes conviction.
Wrapping things up
Well this is the end of this series. Well done on reading thus far!
For those of you who are disappointed that there is not a checklist at the end of this … you are precisely the people we are talking about! What we need to collectively do is start valuing critical thinking. Empowering engineers to do what their head tells them to do. If they can justify doing one thing and not the other – this should be rewarded.
Conversations like this one are imperative for making change. And we need to change as a society. Things are never ‘reliable’ or ‘safe.’ Reliability and safety is not an absolute. It is a metric that informs how much value we put into something. And if we start with working out what we value and then work down, we rarely get it wrong.
And the reality is that the things talked about in this series start at the top. By which I mean management. If you (as a manager) don’t trust your engineers to make the right decisions, then it is your fault for hiring them and then choosing not to train them or ultimately fire them if they can’t learn. It is that simple.
And what we are talking about is not easy. Human beings tend to crave conformity whether it be fashion sense or social norms. Doing something different than your competitors is hard, even if you are all doing the wrong thing. And if you lack the courage to be different (as in – better), then you will often find yourself investing time and money on things that you want to solve. Not things that need to be solved. Because you need to feel good about doing something. And a system that fails spectacularly is tomorrow’s problem.
What I hope you have now is an appreciation as to why compliance-based mission or reliability assurance frameworks don’t work. They never have, and never will. But with great power (or knowledge) comes great responsibility. So what are you going to do about it?
Firstly, focus on performance. What is it that your company or product does? How do you make money? If your satellite fails three months into a six-month mission, how much does that cost you including things like lost future sales? If your satellite is still working three months after a six-month mission, how can this make you money? How much does it cost for a satellite to last longer than a six-month mission? Does this outweigh any benefit you get when you do?
Engineers are smart. Once they know what you as the management team value, they can quickly work out what they should do. If you (as a manager) get angry and withhold bonuses if the product is not shipped on time, then you value time to shipping. You don’t value anything else. And your engineers will work towards what you value. If you communicate what it is you value, the chances are it is only a matter of time before your engineers catch on.
The second thing you can do is reward and demand critical thinking. And this does not mean congratulatory emails or a well done at company lunches. If you rely on your engineers working on weekends to improve your organization’s processes, then you have already lost the battle. Yes, you will routinely get local heroes who go beyond their job description and weekly workload to improve your processes. And if you promote these people, then essentially everyone in your company must be a local hero who works 10-hour days, seven days a week. Is this what you want? Or more importantly, is this what the smart engineers you are hoping to attract want? If the answer is no, you will quickly empty your organization of all your smart engineers.
Instead, critical thinking must be a part of your organization’s process. Ensure that people are allocated either full or part time to challenge the status quo, identify lessons learnt and update the entire organization. Ensure there are people whose main role is to identify best practice in a scientific way.
I have engaged many organizations who lament that standards and assurance frameworks are wrong, outdated and written by the wrong people. But when I ask most them what things need to replace these standards – I get a blank face. It is not their job I hear. They don’t have time is something else I hear.
Customers often reward critical thinking. There are many cases where customers will listen to a manufacturer explain why they only partly comply with an outdated framework. Never underestimate the power of a cogent argument. So make one! Oh and by the way, this requires critical thinking.

Leave a Reply